The test-driven development for writing bug-free CFD code
In this article, we will put the knowledge that we gained from the previous article on software testing principles into practice, and learn about different software project management approaches, that prioritise testing differently. We will see that there are two competing approaches available, the waterfall and agile approach, where the waterfall approach leaves testing to the last item on a to-do list, while agile software development promotes testing to be an integral part of the development process.
Agile software development can be implemented in many ways, and we look at the most common approach, which is the test-driven development (TDD) approach. We implement a simple class and tests for it in this article and exemplify how you would use TDD in your own coding workflow.
By the end of this article, you will have a good understanding of how to use test-driven development for your own projects and be able to write unit tests for them. These will give you the confidence to refactor your code, which is an essential part of programming to ensure your codebase does not deteriorate over time as you add new code.
All developed code and resources in this article are available for download. If you are encountering issues running any of the scripts, please refer to the instructions for running scripts downloaded from this website.
- Download: Software-Testing-Part-1.zip
In this series
[custom_category_posts_list category_slug="the-complete-guide-to-software-testing-for-cfd-applications"]In this article
Software development philosophies
In our previous article, we discussed some of the fundamental principles of software testing. We talked about manual and automated testing, and specifically, about unit, integration, and system testing when it comes to automated testing. We looked at the different testing approaches and classified them into white-box and black-box testing, and concluded that we want to have a mix of both to avoid regressions (bugs) in our code.
Having an idea about the different testing approaches helps us understand how we can protect our code against regressions, but it does not provide us with a plan for how we can integrate tests with our development process. Since we want to have our test code separate from our production code (e.g. the CFD solver we want to write), we need to think about how we are going to develop both of them and integrate them against each other.
When it comes to software or project management approaches, there are two competing principles, the waterfall and the agile approach. The waterfall approach was coined during the 1950s while the agile approach is much newer, introduced in the 2000s, and most software development projects use the agile development approach these days.
The waterfall approach
Let's look at the waterfall approach first. It is shown schematically below:

Here, we follow a specific flow from the left to the right, completing each phase before moving to the next one. We start by gathering requirements for what our software should do (e.g. we want to develop a 3D, unstructured, parallelised CFD solver for aerospace applications), and then put these requirements into a system design that we can use to implement the requirements into code.
Once both of these stages are complete, we start implementing the requirements, and if we are working in a team of a few programmers, then everyone will work on their feature until completed. Once everything is implemented, we test the code to make sure it is working (and we can use the approach we introduced in the previous article) and if we are happy that everything is working, we have to put all the different developments together into one single codebase. With the software finished, we make it available to users, wait for bug reports and maintain the software.
A significant amount of time can pass from gathering the requirements to deploying the software. What if you get feedback halfway through the development process that you want to support not just unstructured grids, but also structured grids? That is going to change how you store the mesh and how you loop over it. This will have ripple effects and affect each part of the code that is already written.
The waterfall approach works best if you know requirements are not going to change. This is rarely the case and thus a more flexible approach is needed.
The agile approach
The flexibility requirement introduced us to the agile software development process. Agile is a buzzword and can mean different things, you may come across terms like Scrum, Kanban, or lean development. They all embody the concept of agile development but with different implementations. The agile software development process is shown below schematically:
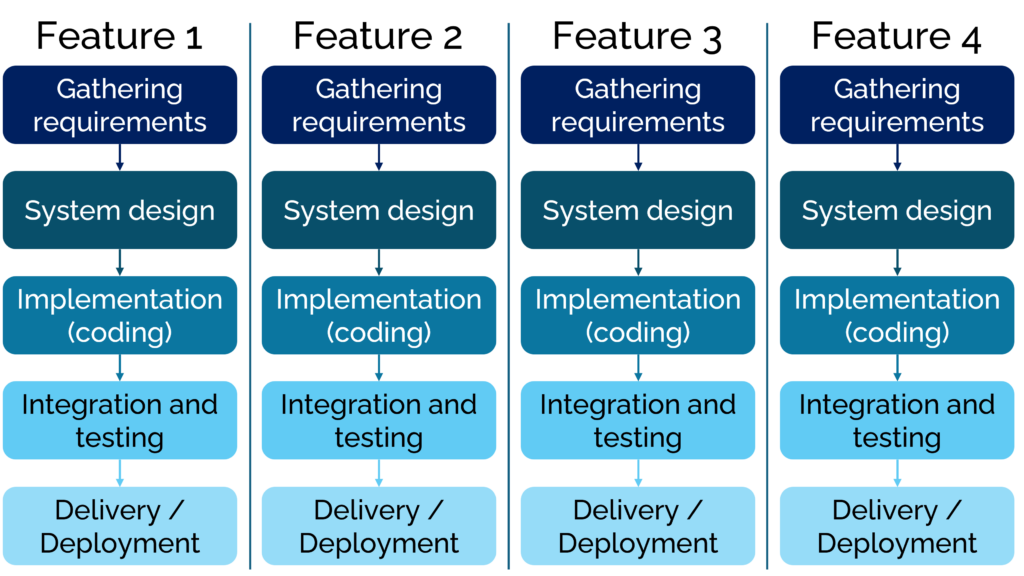
This approach essentially follows the waterfall approach but it breaks tasks down to small units that can be worked on and implemented in a much smaller timeframe. Crucial to agile software development is the requirement that once a feature is completed and tested, however small it may be, it gets integrated into the main codebase.
If the requirements change, then so will the features that need to be worked on. Following Scrum, a popular implementation of agile development, a product backlog is developed, which contains all the features that need to be implemented to get to the final product. In our example, writing a 3D, unstructured, parallelised CFD solver for aerospace applications, we may have features such as: implement Spalart-Allmaras turbulence model, implement MPI parallelisation class, implement the unstructured mesh reading class, and so on.
These features get typically further subdivided into smaller tasks so that they can be completed in a few days. All of these features are stored in the backlog and worked on in a sprint. A sprint lasts for 2 weeks and during this time, the most important features are implemented. During the sprint, new requirements may arise, which were not foreseen, for example, implementing a workaround because one of the libraries that the solver depends on has a bug and can't be fixed quickly.
During the same time, users may also feed back new requirements. If we stick with the example given for the waterfall model, the users may now request to have structured mesh reading as well. In that case, this feature will be put into the backlog and, if it is deemed to be important enough, it will be prioritised in the next sprint. In this way, agile software development can incorporate changing requirements easily and most companies follow this approach nowadays.
One thing that both the waterfall and agile software development process have in common is that they make software testing an integral part of the process. During agile testing, though, we test our code much more frequently and thus radically rewriting the codebase is less of a problem as any regression we are introducing in the rewrite (also called refactoring), will hopefully be captured with our tests.
Now that we have an idea of how to develop software, let's look at implementations of the agile software development process to help us speed up our coding.
The test-driven development (TDD) approach
There are quite a few different software testing philosophies out there, of which the test-driven development (TDD) approach is probably the most widely adopted one. In close relation, there is also the behaviour-driven development (BDD) approach, which tests for the observable behaviour of the code rather than the implementation.
The TDD approach comes from extreme programming (XP), a framework particularly suited for agile software development. The essence of TDD is that before we start writing any code for our production code (e.g. our CFD solver), we start by writing a test first, that will test that the feature we are about to implement is working correctly. Since the feature is not yet implemented, this code will not pass. In fact, at this stage, the test won't even compile.
This gives us a big advantage; writing the test code first allows us to think about the interface, i.e. how we want users to interact with this feature in the code. What are the names of the functions, which order do they have to be called in, and what arguments need to be passed to the functions?
After we have provided the test, we start by implementing the feature until we believe it is complete and ready. At this stage, we don't care if the code is tidy or not, we only focus on getting the code to work. We then run the test (or tests if we have more than one) and check that the code is working as expected. If it isn't, then we go back to the code, debug it, and test again. We repeat this cycle until the test code passes.
Once we are happy that everything is working as expected, we start cleaning up our code and try to make it as readable as possible, by reconsidering names for variables, encapsulating parts of the code into functions, and so on. Since we know the code is working, we can test it quickly after each change to ensure it is still working. once we are finished with this feature and happy it is still working, we move on to the next feature.
If you do this for a few features, you will realise that at some point you have to start editing code that you wrote before, if you are trying to clean up your code. This is a normal process, but since you have tests in place that will check that the code you are modifying is still working after you have touched it, you have the confidence to do so.
This process of refactoring old code is vital to ensure your codebase stays clean and does not deteriorate over time. If you don't take care of your code and rewrite it often, you will end up with code that even you can't understand anymore, I guarantee it. We need testing to give us the courage to refactor old code and test-driven development gives us the confidence to do so.
The problem with floating point numbers
If you followed the previous series on how to read a structured and unstructured grid using the CGNS file format, you may remember that once we came to the point of testing our coordinate reading implementation, I used a little trick to compare floating point numbers. I said that if we know that the coordinate should be, say, x=0.25, then we could read the coordinate, subtract 0.25 from it, take the absolute value and then check if the absolute difference is less than a specific tolerance, in our case, I picked 1e-2 as the tolerance.
I did mention that checking floating point numbers is a tricky business and so I thought, for completeness, I wanted to show you in this article why. There is a detailed and good write-up of this issue, and I won't go as far as this article is with my explanation, so if you are interested, have a look at it. But I want to cover just enough so that we have an appreciation. Later, we will replace this implementation by a testing framework, which will do this heavy lifting for us.
Take the value of x=1.0/7.0. What will this fraction evaluate to? It is a rational number, and if you try to write it out as a decimal number (or floating point number), it is a number that never ends, i.e. we have x=0.142857142857142857... where the first 6 digits just keep repeating. Since we have a finite length of digits that a float (single-precision) or double (double-precision) can store, trying to store the result of 1.0/7.0 in a float or double will result in round-off errors.
Another issue is trying to add numbers together that have vastly different orders of magnitude. Take for example the following code, and try to compile and run it yourself:
int main() {
float a = 1000.0;
float b = 0.001;
float c = a + b;
std::cout << c << std::endl;
return 0;
}Using g++ version 13.2 on a 64-bit platform results in c being printed as 1000.0. Why? Because the float can, at most, hold about 7 significant digits. Try adding or removing some zeros and see the results. You can also try to use a double, which can hold more significant digits. But the point is, even if we expect the above calculation to evaluate to 1000.001, this is not necessarily what is stored in our floating point number.
Thus, we need to have a mechanism, by which we can compare floating point numbers. A naive approach may be to say that, similar to what we did in the CGNS coordinate reading test, we simply compare the difference between two floating point numbers against some tolerance, and if it is smaller than the tolerance, then we deem these numbers to be equivalent.
There is just one issue with this approach, and that is that depending on the magnitude of the numbers. The smallest difference between floating point numbers that can be resolved changes with the magnitude. Let's return to our example above and expand on it:
int main() {
float a = 1000.0;
float b = 0.001;
float c = a + b;
std::cout << c << std::endl;
float d = 1000000.0;
float e = 1.0;
float f = e + d;
std::cout << f << std::endl;
return 0;
}We now introduce an additional addition of floating point numbers on lines 7-10. But now, we are trying to add 1.0, instead of 0.001, to a number. The number we are trying to add it to is 6 orders of magnitude larger than 1.0. On lines 2-5, the order of magnitude between the two numbers we are trying to add is also 6. When we try to print line 10, we get the result 1000000, and not 1000001. Thus, as the order of magnitude of the numbers increases, so do the smallest differences between floating point numbers that we can resolve.
Implementing a floating point comparison algorithm
With this newfound knowledge, we can now start to implement an algorithm that can compare two different floating point numbers. The algorithm is shown below and will require some additional explanations:
#include <limits>
#include <cmath>
template<typename T, typename std::enable_if_t<std::is_floating_point<T>::value>* = nullptr>
bool floatingPointEqual(T A, T B) {
const T difference = std::fabs(A - B);
A = std::fabs(A);
B = std::fabs(B);
const T largestValue = A > B ? A : B;
const T maxRelativeDifference = std::numeric_limits<T>::epsilon();
if (difference < largestValue * maxRelativeDifference)
return true;
return false;
}Let's ignore the template magic we perform on line 4 and return to that later. If you need a refresher on templates, though, have a look at my article on template programming in C++. Suffice it to say, at this moment, that the template argument T on line 4 is either a float or a double.
The function expects two floating point numbers A and B and the algorithm is as discussed above, i.e. we first take the difference on line 6 and ensure that we are dealing with positive numbers only on lines 7-8. We then check which of the two values of A and B is the largest one on line 9.
On line 10, we check what the smallest difference is that a floating point number of type T (i.e. either float or double) can resolve. This smallest value is normed for a value of 1.0 and so increases or decreases as we move away from this value, as we saw above in our motivating example. The smallest difference epsilon a floating point number can resolve is defined in the <limits> header.
On line 12, we scale the range by how much a floating point number is allowed to differ using the largest value of the two floating point numbers we want to compare, that is, we multiply both together. We now only have to compare if this new tolerance is larger than the tolerance difference we have calculated. If that is the case, then we can state that the floating point numbers are the same and we return true from the function, otherwise, we return false.
If you want to have some additional security, you may want to multiply this scaled version largestValue * maxRelativeDifference by some integer value to allow a slightly larger difference.
OK, let's go back then to line 4 and look at the template arguments specified here. The first argument is T, and as previously mentioned, that will be a floating point type, e.g. float or double. But what about the second argument? What does this typename std::enable_if_t::<std::is_floating_point::value>* = nullptr achieve? This is a special template programming trick we can employ in C++, which is known as substitution failure is not an error, or SFINAE.
Great, one more acronym, but what does it achieve? SFINAE allows us to make functions visible only if certain conditions are met. That's it. It is like an if/esle statement, only using templates. Remember, templates are just placeholders for types and allow us to define a function once but accept different types. Thus, SFINAE simply tests if the function is called with a specific variable type, and if it is, then this function will be defined, otherwise, it won't.
Let's look at the expression again, typename std::enable_if_t::<std::is_floating_point::value>* = nullptrT (specified as the template argument before on line 4), is a floating point type, i.e. float or double. If it is not, for example, we call it wit T being an int or and unsigned type, the function will not exist.
We need to remember here that template functions do not exist, they are only used to instruct the compiler to create functions from our templated function. The template function is like a blueprint of a house, it shows in drawings how the house will look like when it is built, but it doesn't exist in reality, it is just a drawing. Template functions are the same, only the compiler can generate the actual functions for us from the templates. Using SFINAE, we can restrict the functions that will be constructed, and in this case, we say we don't want to have a version for integer numbers, because we can compare them directly.
Since the C++20 standard, we have support now for concepts, which were introduced to make SFINAE a lot more user-friendly, both in terms of syntax, but also in terms of error messages should we try to call a function that doesn't exist. I thought I show you here to classical way of defining SFINAE code, because that is still the majority of code examples you will find on the internet. I haven't shifted to the new syntax yet but I likely will adopt concepts in the future if we need it again.
Walkthrough: How to implement test-driven development into your development
Ok, we have now an idea about how to develop a project and how to apply the test-driven development approach. Let's put that to the test and work on a very simple project.
When we deal with signals in our CFD code, be it from recording velocity and pressure fluctuation at a specific point, or lift and drag values from a body that periodically sheds off vortices, we typically want to obtain the frequencies that are present in the signal. To do so, we need to perform a Fourier transform, which is typically implemented as a fast Fourier transform (FFT). The FFT spits out complex numbers, and even if we have support for complex numbers in the C++ standard template library, they serve as a good example to write our own complex number class in a test-driven development approach.
This is what we are going to do in this example. First, we will write tests for all possible features we need, which are
- Adding two complex number
- Subtracting two complex numbers
- Multiplying two complex numbers
- Dividing two complex numbers
- Taking the magnitude of a complex number
- Conjugating a complex number
Since we are going to write a class for complex numbers only, which will have at least 6 functions as seen above, we will provide unit tests for each of these functions. If we wanted to also write some integration and system tests, we would need a much larger project to work on, but at this stage, I want to keep things simple, thus we will only provide unit tests. We will look at more complex examples in the next articles, where we will provide unit, integration, and system tests.
In the following, we will look at the project structure, the build scripts required, and then start with writing our tests, following the test-driven development approach. Once all tests are written and failing, we start writing implementations for all of the features we are testing without tests and finish once all of the tests pass.
Project structure
The project structure for the code you can download above is given in the following. The root folder contains two subdirectories called src and tests. The src directory contains a single file, named complexNumber.hpp which is the implementation of the complex number class. in this case, we keep things simple and implement all functionality into the header file. This is similar to header-only libraries, which we discussed a while back.
The tests folder contains the floatingPointEqual.hpp file, which we discussed above to compare two floating point numbers, and we have the unit folder, which contains all of our unit tests. In this case, we only have a single file called testComplexNumbers.cpp, in which we will define all the unit tests for the complex number class. We also see the build scripts we mentioned above, and these sit in the root folder. One for compilation on Windows, and one for compilation on UNIX systems.
root
├── src
│ └── complexNumber.hpp
├── tests
│ ├── floatingPointEqual.hpp
│ └── unit
│ └── testComplexNumbers.cpp
├── runTests.ps1
└── runTests.shBuild scripts
We have now looked at quite a few build scripts, both for Windows and for UNIX, so we will keep this discussion short. If you need a refresher on the different build steps and compiler flags, have a look at the article when we looked at our first build scripts. I spent quite some time explaining the build scripts there in detail and the following ones are not that different, if anything, the following build scripts are probably much simpler.
Windows
For Windows, we follow a similar approach to previous projects, which is, to first delete any build folder if it exists (lines 2-3), then compile the source files, which in this case is only the unit test (line 6) and then link all object files, which again in this case is only coming from the unit test on line 9. The reason we only compile the unit test, and not the complex number class, is that the complex number class is defined in the header file and this is injected directly into the complex number unit test source file. On line 12, we execute the executable produced from our test code.
# clean up before building
Remove-Item .\build -Force -Recurse
New-Item -Name "build" -ItemType "directory"
# compile source files into object files
cl.exe /nologo /EHsc /std:c++20 /I. /c /O2 .\tests\unit\testComplexNumbers.cpp /Fo".\build\testComplexNumbers.obj"
# create test executable
cl.exe /nologo /EHsc /std:c++20 .\build\testComplexNumbers.obj /Fe".\build\testComplexNumbers.exe"
# run tests
.\build\testComplexNumbers.exeUNIX
Our UNIX bash script is much the same, i.e. we remove the build folder if it exists on lines 4-5, compile the source file for the unit test on line 8 and link all object files (again, just the single one from the unit test) into an executable file on line 11. We execute the code on line 14.
#!/bin/bash
# clean up before building
rm -rf build
mkdir -p build
# compile source files into object files
g++ -std=c++20 -I. -c ./tests/unit/testComplexNumbers.cpp -o ./build/testComplexNumbers.o
# create test executable
g++ -std=c++20 ./build/testComplexNumbers.o -o ./build/testComplexNumbers
# run tests
./build/testComplexNumbersWriting the test
At this stage, we haven't written any code. We have defined all files but the complex number class file is empty. As I mentioned previously, in test-driven development we start by writing tests first and only then start to implement the class and functions that are required to make the test pass. We can see the code for the complex number class tests below, which test each of the functions we said are required for this class.
#include <cassert>
#include <iostream>
#include "tests/floatingPointEqual.hpp"
#include "src/complexNumber.hpp"
void testComplexMagnitude() {
// Arrange
ComplexNumber a(3.0, 4.0);
// Act
auto magnitude = a.magnitude();
// Assert
assert(floatingPointEqual(magnitude, 5.0));
}
void testComplexConjugate() {
// Arrange
ComplexNumber a(3.0, 4.0);
// Act
a.conjugate();
// Assert
assert(floatingPointEqual(a.Re(), 3.0));
assert(floatingPointEqual(a.Im(), -4.0));
}
void testComplexAddition() {
// Arrange
ComplexNumber a(1.2, -0.3);
ComplexNumber b(1.8, 5.3);
// Act
ComplexNumber c = a + b;
// Assert
assert(floatingPointEqual(c.Re(), 3.0));
assert(floatingPointEqual(c.Im(), 5.0));
}
void testComplexSubtraction() {
// Arrange
ComplexNumber a(1.2, -0.3);
ComplexNumber b(1.8, 5.3);
// Act
ComplexNumber c = a - b;
// Assert
assert(floatingPointEqual(c.Re(), -0.6));
assert(floatingPointEqual(c.Im(), -5.6));
}
void testComplexMultiplication() {
// Arrange
ComplexNumber a(1.2, -0.3);
ComplexNumber b(1.8, 5.3);
// Act
ComplexNumber c = a * b;
// Assert
assert(floatingPointEqual(c.Re(), 3.75));
assert(floatingPointEqual(c.Im(), 5.82));
}
void testComplexDivision() {
// Arrange
ComplexNumber a(1.0, -2.0);
ComplexNumber b(1.0, 2.0);
// Act
ComplexNumber c = a / b;
// Assert
assert(floatingPointEqual(c.Re(), -0.6));
assert(floatingPointEqual(c.Im(), -0.8));
}
#include <complex>
int main() {
testComplexMagnitude();
testComplexConjugate();
testComplexAddition();
testComplexSubtraction();
testComplexMultiplication();
testComplexDivision();
std::cout << "All tests passed!" << std::endl;
return 0;
}Let's look through the file in more detail, we have specified 6 unit tests in this file. On lines 7-16, for example, we test that we can get the correct magnitude, lines 18-28 test that the complex conjugate is correctly formed, lines 30-41 test for complex addition, and so on. All of these test functions are called from the main() function between lines 84-95. If none of these functions fail, then we print a success message to the console.
Let's look at the complex addition, then, as an example, shown below for simplicity:
void testComplexAddition() {
// Arrange
ComplexNumber a(1.2, -0.3);
ComplexNumber b(1.8, 5.3);
// Act
ComplexNumber c = a + b;
// Assert
assert(floatingPointEqual(c.Re(), 3.0));
assert(floatingPointEqual(c.Im(), 5.0));
}We follow the AAA structure, i.e. arrange, act, assert. In the arrange section, we set up everything we need for this test, in this case, we need two complete numbers, here labelled a and b. In the act section, we create a new complex number c, which simply adds both complex numbers a and b together. In the assert section, we want to assert that certain numbers are the same. We use here the floatingPointEqual() function that we defined above so that we can compare floating point numbers.
Remember, at this point, we haven't provided any implementation for the complex number class, but this unit test exposes a specific interface that we now need to implement. Unit tests are excellent in helping to design a class interface that is intuitive and easy to use, and it makes sense that we do this sort of interface design before we write any class code.
We see that we want our constructor to accept two numbers, one for the real, and one for the imaginary part. Next, we also see that we want to be able to add two numbers together, hence, we need to overload the addition operator, i.e. operator+(). Finally, in the assert section, we see that we want to be able to retrieve the real part using the Re() function and Im() to get the imaginary part.
These two functions will be simple getter functions, and we could have just as well called them getReal() and getImaginary() to follow C++ conventions. However, Re() and Im() follows conventional mathematical notations and so we use that. getReal() also sounds rather strange as a function name and our job is not to confuse the end user.
The remaining tests follow the same AAA pattern and test various other functionalities of the complex number class. You will see that our unit tests largely follow the same syntax and patterns so once you understand one test, you should be able to understand the remaining tests without problems.
One last observation: we said that if we want to have a unit test, we should only ever have a single line of code in the act section. There may be occasionally a good reason as to why this can't be achieved, but in this case, we see that this condition is met here and we only ever use a single instruction.
Writing the implementation
The class interface and its implementation are given below. Even though it is a header file, we can always provide all code just in header files. In this case, it is done to keep the implementation simple and in one file, but we could have also separated the class interface into a separate header file and then implemented that interface in its own source file. Have a look through the file, and then we'll discuss it below.
#pragma once
#include <iostream>
#include <cmath>
class ComplexNumber {
public:
ComplexNumber(double real, double imaginary) : _real(real), _imaginary(imaginary) { }
~ComplexNumber() = default;
double Re() const { return _real; }
double Im() const { return _imaginary; }
void conjugate() { _imaginary *= -1.0; }
double magnitude() const { return std::sqrt(std::pow(_real, 2) + std::pow(_imaginary, 2)); }
ComplexNumber operator+(const ComplexNumber &other) {
ComplexNumber c(0, 0);
c._real = _real + other._real;
c._imaginary = _imaginary + other._imaginary;
return c;
}
ComplexNumber operator-(const ComplexNumber &other) {
ComplexNumber c(0, 0);
c._real = _real - other._real;
c._imaginary = _imaginary - other._imaginary;
return c;
}
ComplexNumber operator*(const ComplexNumber &other) {
ComplexNumber c(0, 0);
c._real = _real * other._real - _imaginary * other._imaginary;
c._imaginary = _real * other._imaginary + _imaginary * other._real;
return c;
}
ComplexNumber operator/(const ComplexNumber &other) {
ComplexNumber c(0, 0);
c._real = (_real * other._real + _imaginary * other._imaginary) /
(other._real * other._real + other._imaginary * other._imaginary);
c._imaginary = (_imaginary * other._real - _real * other._imaginary) /
(other._real * other._real + other._imaginary * other._imaginary);
return c;
}
friend std::ostream &operator<<(std::ostream &os, const ComplexNumber &c) {
os << "(" << c._real << ", " << c._imaginary << ")";
return os;
}
private:
double _real;
double _imaginary;
};Lines 8-9 define the constructor and destructor. The constructor takes two arguments for the real and imaginary part, which we store in the _real and _imaginary variable defined on lines 53-54. The destructor is the default one, meaning that there isn't anything special for it to do. We didn't allocate any memory on the heap and all variables are defined on the stack. We also don't have any inheritance so the destructor statement is not required, but I just leave it here for clarity. It will still be called, but it won't do anything.
If you need a refresher on what the difference is between the heap and stack, or inheritance, or constructors and destructors, follow the links where I talk about their role in the context of CFD applications.
Lines 11-12 are the two getter functions we defined in our addition tests, which will return the real and imaginary parts from the class, respectively. Lines 14-15 calculate the complex conjugate and magnitude, which simply negates the imaginary part and calculates the magnitude from the real and imaginary part, respectively.
For all of these 4 functions, I have used the convention that if a function only uses a single line for its implementation, we can write the entire function on one line. This keeps the class short and visually separates these one-liners from the rest of the implementation.
Complex addition as an example
Let's look at the complex addition case next. I have copied its code again below so it is easier to follow the discussion. As you can see, we have to overload the addition operator here, as we have already previously established. If you need a refresher on operator overloading, have a look at my write-up, showing again how we may use that in a CFD context, including some excursions to see how OpenFOAM uses operator overloading.
ComplexNumber operator+(const ComplexNumber &other) {
ComplexNumber c(0, 0);
c._real = _real + other._real;
c._imaginary = _imaginary + other._imaginary;
return c;
}We define operator+() function here, which accepts exactly one argument. If you tried to define it without any argument, or more than one argument, then you would get a compilation error. Remember, the operator+() function allows us to write code like we saw in our test before, i.e. ComplexNumber c = a + b;. This is what we saw in our complex number addition test. Here, we could have also replaced the plus sign with ComplexNumber c = a.operator+(b);, which is not as intention-revealing as the first notation.
However, using the second notation helps us to remember that whenever we define any arithmetic operator, that is, for addition, subtraction, multiplication, and division, the overloaded operator accepts exactly one argument, not more, not less.
We define a new complex number here on line 2, and that is the number we want to return at the end of the function, i.e. line 5. Lines 3-4 simply add the real and imaginary numbers together, store that in the new complex number c which is then returned on line 5.
We have this peculiar C++ behaviour here that if we define this function within the ComplexNumber class, which we do, then we are allowed to access the private variables of another object, without having to use a getter or setter function. For example, on line 3, we access the private variable other._real from the complex number we received as an argument to the function. But, because it is of the same type as the class we are currently in, we are allowed to access the private variables directly. The same is true for line 4, where we access the imaginary part.
Looking back at the class interface provided above, the remaining functions follow a very similar pattern and implement all of the complex arithmetic operators. The last function, given on lines 47-50, overloads the operator<<() which is defined in the iostream header file, and thus we need to make it a friend function of our class.
The purpose of this class is to print the content of the complex number to the console. This may be helpful during debugging or if you want to print the result of a computation to the screen.
Should we test everything?
So, if we look through the class, we have 9 functions in total, but only 6 unit tests for them. The functions that did not get their own unit tests are the Re(), Im(), and operator<<() functions.
For the first two functions, which are essentially just getter functions, we said in the previous article that we don't have to provide unit tests. These functions consist of two words, i.e. return + variable name, and we can probably ensure that they are working correctly by just looking at them. If we write the name wrong, we will get a compiler error.
Furthermore, we do implicitly test these functions anyway, for example, when we test our complex addition as we saw before. In the assert section, we received the real and imaginary parts and ensured that it was added up correctly. Thus, even if we don't have a dedicated test for them, they are still tested.
What about the operator<<() function then? This function exists purely for debugging by printing a complex number to the screen. Is this function a necessity to ensure that the complex number class will work correctly? The answer is no, and so it shouldn't be tested.
But you may be tempted to test it anyways, to get this elusive 100% code coverage metric which you can proudly boast to the world, for example, in your GitHub repository. If you have no idea what I am talking about, have a look at this JSON library for C++, and look for the coverage badge.
So let's go through with this and then see why this is a bad idea, and why not testing everything is the right approach. The art is in deciding which code section to test and which to leave without a test. Let's say that we have a complex number defined as
ComplexNumber a(1, 2);What will happen if we print this number now using the syntax std::cout << a << std::endl;? Looking at the implementation of the operator<<() function, we would expect to see something like (1, 2) being printed to the console. Or is it (1.0, 2.0)? Or could it even be (1.0e+00, 2.0e+00)? Let's take a look at a simple example:
#include <iostream>
#include <iomanip>
int main() {
std::cout << "(" << 1.0 << ", " << 2.0 << ")" << std::endl;
std::cout << std::scientific;
std::cout << "(" << 1.0 << ", " << 2.0 << ")" << std::endl;
return 0;
}Here, we simulate printing the complex number (1, 2) on lines 5 and 7 to the console with a little twist; we change the representation on line 6 to a scientific, or exponential representation. Let's look at the output we get printed to the console:
(1, 2)
(1.000000e+00, 2.000000e+00)Now imagine we would want to write a test for that, and we forgot to specify the formatting. We would capture the output of the operator<<() and then compare it against a string, for example, "(1, 2)" in this case. This test may work fine and we move on to the next test. However, we may decide to change the formatting within the operator<<() function later, and now our test for this function will fail.
This is a dangerous test and these types of tests are called brittle tests and we want to avoid them at all costs. A brittle test may fail without indicating that your implementation is wrong. In this case, if our test for the operator<<() would fail, we simply wouldn't get the formatting we were expecting, however, that doesn't tell us anything about the correctness of the rest of the class. For all we know, if all the other tests are succeeding, then our implementation is probably correct and only the printing is broken.
Since the printing is not a core logic for the class to work correctly, we don't test it and we should get into a habit of saying no to tests that don't add value to our test suite. Yet, you will find larger projects all boasting 100% test coverage and you can be assured that there will be some brittle tests buried in there somewhere.
These tests are typically very heavily constrained to ensure the correct output, but this is not testing anymore, this is a futile attempt to chase a 100% test coverage. The alternative is that you take non-essential code out, but that always comes at the cost of user-friendliness.
If we wanted to have 100% test coverage but no brittle tests, we would remove the operator<<() function, and so, instead of being able to write
ComplexNumber a(1, 2);
std::cout << a << std::endl;we now have to write
ComplexNumber a(1, 2);
std::cout << "(" << a.Re() << ", " << a.Im() << ")" << std::endl;I leave it up to you to decide which is easier to read and to implement quickly if you are stepping through your code and just want to print a few numbers to ensure the code is working correctly.
Testing the implementation
With our test written and the implementation for the complex number class provided, we are now in a position to test our code. Using either the Windows or UNIX build script will provide us with an executable called testComplexNumbers.exe (Windows) or testComplexNumbers (UNIX), which will be located in the build directory. If we run this executable file now, we get the following output printed to the console:
All tests passed!This indicates that all implementation was correct and the complex number class is working as expected. Well, it is working as expected for the numbers we have provided, but we haven't tested boundary or edge cases. What if we defined two complex numbers which are zero for both the real and imaginary parts? Then, the division will fail, because of a division by zero. Or, what happens if one of the complex numbers has a NaN (not a number) argument?
The two cases given above are edge cases we haven't tested for. We have only tested the so-called happy path, i.e. what we expect to happen most of the time. If we wanted to make our class more robust, we would be testing these edge cases now as well and then provide an implementation to catch these edge cases.
For example, we could check in the constructor if any of the numbers is NaN, and then throw an exception. Or, in the division case, we can check that the complex numbers will not result in a division by zero situation and throw an exception as well. Finding these edge cases can be difficult and sometimes you'll realise that you haven't tested for everything only after your code is failing unexpectedly.
As a gentle introduction to software testing, though, this should be sufficient and hopefully you got the idea behind the test-driven development approach.
Summary
This concludes this article, where we looked at how to implement the test-driven development (TDD) approach using the development of a complex number class as an example. We started this article by looking at different software management approaches and classified them into either a waterfall or agile approach. Both include software testing, but the agile approach promotes testing to be an integral part of the software development process, whereas the waterfall approach allows all testing to be left for one of the last phases.
The example we looked at in this article is fairly typical. You want to implement a class, so you first think about all the functions that you need and then start writing tests for them. You may want to write all test functions first, or start with one test, implement it, make sure it is working, and then move on to writing the next test. Both are common approaches and will get you to the same result.
We have thus far only looked at very simple test cases, i.e. those that require us to test that two numbers are the same. But what if we wanted to test that a function is throwing an exception? Or what if we wanted to mock a dependency? We would have to write a substantial amount of code to do that, and so in the next article, we will look at how we can use a test framework to make our lives easier.

Tom-Robin Teschner is a senior lecturer in computational fluid dynamics and course director for the MSc in computational fluid dynamics and the MSc in aerospace computational engineering at Cranfield University.


