How to write a CFD library: The sparse matrix class
In this article, we will first look at why sparse matrices, as found in CFD applications, really need to be stored with an adequate sparse matrix storage format, by looking at some back of the envelop calculations that show that we can save a significant amount of data by using an appropriate storage format. We then proceed to look at how we would implement the compressed sparse row (CSR) storage format into a matrix class which we will use to store our coefficient matrix of the 1D head diffusion equation.
All developed code and resources in this article are available for download. If you are encountering issues running any of the scripts, please refer to the instructions for running scripts downloaded from this website.
In this series
[custom_category_posts_list category_slug="how-to-compile-write-and-use-cfd-libraries-in-c"]In this article
How we got here
In the previous two articles, we looked first at how to implement the Conjugate Gradient algorithm, which prompted the necessity of having both a vector and matrix class. We looked at the vector class in the previous article and in this week's article, we'll look at the matrix class, finally. As a reminder, the basic structure of our library is given below with its 4 header and source files, which we described in depth in our basic library structure article.
root
├── build
├── linearAlgebraLib
│ ├── linearAlgebraLib.hpp
│ └── src
│ ├── vector.(hpp|cpp) // previous article
│ ├── sparseMatrixCSR.(hpp|cpp) // current article
│ ├── linearAlgebraSolverBase.(hpp|cpp) // 2nd previous article
│ └── conjugateGradient.(hpp|cpp) // 2nd previous article
├── main.cpp
└── buildAndRun.(sh|bat)Sparse vs Dense matrices
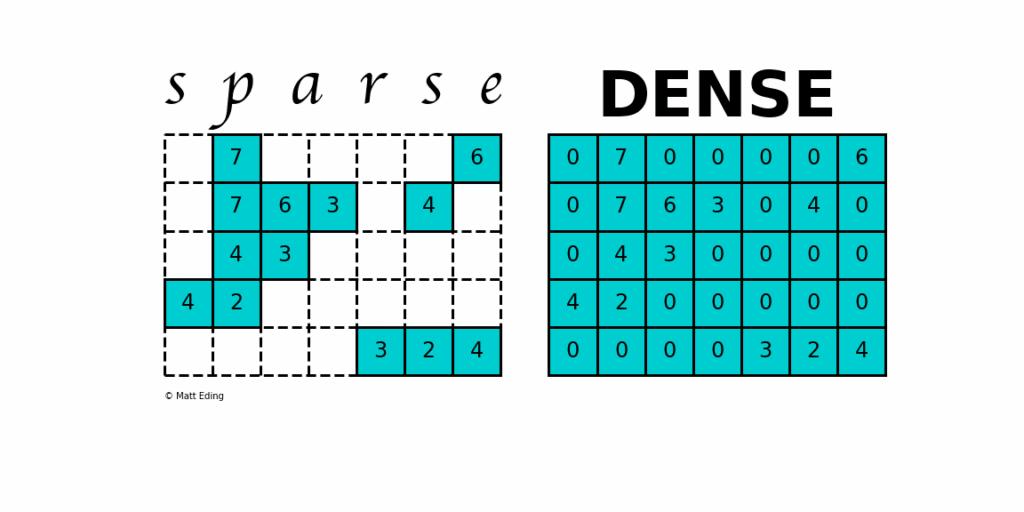
Before we dive deep into the implementation of our matrix class, I want to spend some time first describing how we store our matrix, and why. For this, we need to first recap the differences between a dense and a sparse matrix. In the following, I have taken images from Matt Eding's article on Sparse Matrices, which in itself is a brilliant read and highly recommended. It goes beyond what we need but shows different ways to store matrices. We'll only look at what is the commonly accepted practice in the CFD community, but this may be a good article for background reading.
The picture below depicts a sparse and dense matrix. The difference is that a dense matrix stores all its elements, regardless of their value, whereas a sparse matrix recognises that there are elements which are zero and do not need to be stored. This saves memory and ultimately computational resources. CFD applications always produce sparse matrices and so we need a mechanism to store them efficiently. The figure below shows empty spots in the sparse matrix we don't want to store, while these zero elements are stored for the dense matrix.
Sparse matrices in CFD applications
Let's look at some typical matrix patterns in CFD applications. When we discretised the 1D heat diffusion equation, we ended up with the linear system of equations [katex]\mathbf{Ax}=\mathbf{b}[/katex]. We saw that the matrix [katex]\mathbf{A}[/katex] here contained all the coefficients from the discretised equation, and this implicitly stores the information about which equation is solved, as well as which numerical schemes are used to solve this equation. We also looked at the structure of that matrix, which is repeated below for convenience
\begin{bmatrix}a_0 & a_1 & & & \dots & \\ a_0 & a_1 & a_2 & & & \vdots \\ & a_1 &a_2 & a_3 & & \\ & & & \ddots & &\\ \vdots & & & a_{k-2} & a_{k-1} & a_{k} \\ 0 & \dots & & & a_{k-1} & a_{k} \end{bmatrix} \begin{bmatrix}x_0 \\ x_1 \\ x_2 \\ \vdots \\ x_{k-1} \\ x_{k}\end{bmatrix} = \begin{bmatrix}b_0 \\ b_1 \\ b_2 \\ \vdots \\ b_{k-1} \\ b_{k}\end{bmatrix}This matrix only stores elements on the diagonal and then to its immediate left and right neighbours. That is, if we are on row [katex]i[/katex], we only store elements at column [katex]i-1[/katex] and [katex]i+1[/katex]. All other entries that are at [katex]i\pm 2[/katex] or above/below, are zero.
Sparse matrices for structured grids
Let's look at a structured, 2D grid, and how the matrix would look in this case. Below is an example of a 4 by 4 2D mesh, and we are focusing on cells 6 and 16 here. We show its direct neighbours, and then how the matrix structure would look like. We use colours to highlight where in the matrix each element is stored.
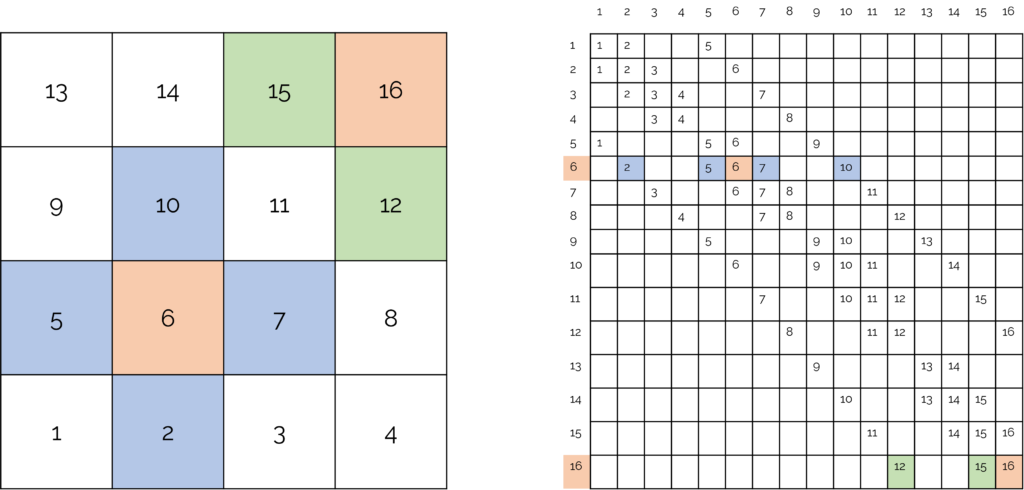
For each cell, we store the neighbours of cell [katex]i[/katex] in row [katex]i[/katex], and we use the [katex]j[/katex] index to identify neighbouring cells. If we go back to our article on discretising the 1D heat diffusion equation, we see that we ended up with the following equation
T_{E}^{n+1}\left(\frac{\Gamma A}{\Delta x}\right)+T_P^{n+1}\left(\frac{-2\Gamma A}{\Delta x}\right)+T_{W}^{n+1}\left(\frac{\Gamma A}{\Delta x}\right)=0We can use this equation and rewrite it to make sense for our matrix structure given above. Since we only have a 1D problem, we'll only have direct neighbours to the left and right of the main diagonal. In [katex]i, j[/katex] notation, the above equation would read as
T_{i,j+1}^{n+1}\left(\frac{\Gamma A}{\Delta x}\right)+T_{i,j}^{n+1}\left(\frac{-2\Gamma A}{\Delta x}\right)+T_{i,j-1}^{n+1}\left(\frac{\Gamma A}{\Delta x}\right)=0With this notation, we need to further set [katex]i=j[/katex], and so the main diagonal is represented b [katex]T_{i,j}[/katex]. It's neighbouring neighbours are [katex]T_{i,j-1}[/katex] and [katex]T_{i,j+1}[/katex], and all values given in parenthesis are the actual values we store in the coefficient matrix at locations [katex]i,j-1[/katex], [katex]i,j[/katex], and [katex]i,j+1[/katex].
Returning back to the above figure and focusing on cells 6 and 16 (orange), that means we have to go to row 6 or 16 in our coefficient matrix. Cell 6 is stored at [katex]i=6, j=6[/katex] and so we always have a main diagonal in a sparse matrix for CFD applications. The neighbours to the left and right are in cells 5 and 7, and thus, still on row [katex]i=6[/katex], we also have entries at [katex]i=6, j=5[/katex] and [katex]i=6, j=7[/katex], shown in blue. We end up with an additional diagonal band to the left and right due to neighbours above and below cell 6. Here, we also have neighbours in the form of cells 2 and 10, and thus have additional entries at [katex]i=6, j=2[/katex] and [katex]i=6, j=10[/katex].
For cell 16, the situation is similar, but we focus here on a cell which sits on the boundary. Cell 16's neighbours are again found on row 16 in the coefficient matrix, and we see that only cell 12 and 15, stored at locations [katex]i=16, j=12[/katex] and [katex]i=16, j=15[/katex], are present in the coefficient matrix. Structured grids always have this banded structure.
Sparse matrices for unstructured grids
Unstructured grids, on the other hand, have no clear ordering of neighbours so their sparse matrices look somewhat random. Below is an image that shows typical matrix structures for structured and unstructured matrices, to compare their form. Here, we simply visualise all elements that have a non-zero value with a blue dot and zero values are not shown. This allows us to see the sparse matrix structure.
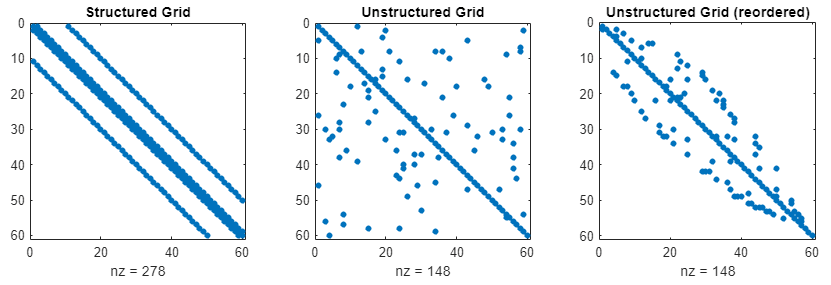
We already saw the structured grid example above, but can summarise here that if we had more elements in our stencil, or had a 3D mesh which contained more neighbours, we would end up with simply more bands to the left and right of the main diagonal. The unstructured grid still has a main diagonal as we always have elements at [katex]i=j[/katex], i.e. when we loop over our mesh, this is the cell for which we are computing the solution and all other cells are just neighbours of this cell. However, the randomness in locations presents two issues for us if we were to store the matrix in this form:
- We incur a lot of cache misses if we store the matrix in its random structure (see also my article on memory management in C++ which explores the role of memory in more depth and why efficient memory management is mandatory for CFD applications)
- We increase the number of communications for inter-processor boundary exchanges if we want to parallelise our code with MPI (Messenger Passing Interface).
Thus, we would like to get back to this banded structure we have with structured grids, so we typically reorder our unstructured grid for efficiency. This is shown on the right on the plot above, i.e. the middle and right matrix are the same matrix, the right one is just a reordered version of the middle matrix. Here, I used the reverse Cuthill-McKee algorithm, which is the standard matrix reordering algorithm in all CFD applications.
The cost of dense matrices and how sparse matrices save the day
Now that we have some understanding of the structure of sparse matrices, let's get a feeling for how much storage they save. We can come up with this simple equation that calculates the number of non-zero elements in our matrix
nonZeroElements = numberOfCellsInStencil * numberOfCells
The numberOfCellsInStencil variable contains the cell for which we want to compute the solution (i.e. the element on the main diagonal) and all its neighbours. In 1D, we always have 2 neighbours so our stencil size is 3 (1 central cell + 2 neighbours), unless we consider a higher-order numerical scheme which requires more than just the direct neighbours in the stencil. In our 2D structured grid example above, the numberOfCellsInStencil variable is 5, 1 central cell plus 4 neighbours, one to each side of the central cell's faces. In 3D, this would expand to 7 (6 neighbours in total for a cube, i.e. it has 6 faces and so 6 neighbours).
Unstructured grids can, on the other hand, have any number of neighbouring cells, as the cells themselves can be anything from a triangle in 2D (3 faces, thus 3 neighbours), to an infinitely large polyhedra in 3D. Commonly, polyhedra cells can have 12 faces which serves as a good approximate average value.
With that in mind, we can define the sparsity of a matrix as
sparsity=1-\frac{nonZeroElements}{numberOfCells^2}Let's do this for a couple of examples. Let's assume we want to solve a problem on a mesh with 1 million elements. Let's consider 1D, 2D, and 3D grids, with line (1D), triangle (2D), hexahedron (3D) and polyhedron (3D) cell types. Each cell type will have a different number of elements in their stencel, namely: line (2 neighbours), triangle (3 neighbours), hexahedron (6 neighbours) and polyhedron (12 neighbours). Furthermore, we assume that we want to store double-precision values of type double, each being 8 byte in size. Thus, if we wanted to store this coefficient matrix as a dense matrix, we would have to store 1 million * 1 million values of 8 bytes, resulting in storage requirements of 8 Terabytes for the coefficient matrix alone.
We can't handle that much memory, as we are always limited by the amount of memory in our random access memory (RAM) poll. Our applications always get loaded into RAM before execution, and the last time I checked, RAM was still measured in Gigabytes, not Terabytes. And even if we had TeraBytes of memory available, we are only talking about a 1 million cell mesh here, this is still rather small. So, we need something better, let's calculate the storage requirement then for the above-mentioned cells and see how sparse matrices can help us save the day.
- 1D structured, line elements, numberOfCellsInStencil = 3: nonZeroElements = 3 million, sparsity = 99.9997%, Storage = 24 MegaBytes
- 2D unstructured, triangle, numberOfCellsInStencil = 4, nonZeroElements = 4 million, sparsity = 99.9996%, Storage = 32 MegaBytes
- 3D structured, hexahedron, numberOfCellsInStencil = 6, nonZeroElements = 6 million, sparsity = 99.9994%, Storage = 48 MegaBytes
- 3D unstructured, polyhedron, numberOfCellsInStencil = 12, nonZeroElements = 12 million, sparsity = 99.9988%, Storage = 96 MegaBytes
Instead of measuring memory in TeraBytes, our sparse matrices with sparsity well above 99.99% have now storage requirements that are less than 100 MegaBytes (it is actually going to be slightly larger, as we need to store additional information for such as the location of the values in the matrix, but the order of magnitude will remain the same). That easily fits into our memory. This shows that we really want to store our matrix as a sparse matrix, rather than a full, dense matrix. In the next section, we'll explore how we achieve just that.
Storing sparse matrices efficiently
We saw that we really want to use a sparse matrix structure to save storage. But how do we store these matrices then? Just storing the non-zero values is no good, as we have no information about where in the matrix these values are stored. So we need to come up with additional information that helps us identify where in the matrix these non-zero values are stored. We look at two examples below, one simple and one more advanced concept. As you may have already guessed, CFD always likes to favour the more complicated type, so we use the simple example to prepare us to understand the more advanced concept.
The coordinate matrix
The coordinate matrix is probably the simplest of all sparse matrix formats. What we do in this case is simply store the data (i.e. the non-zero elements of the matrix), along with its [katex]i,j[/katex] coordinate in the matrix. The image below demonstrates this data structure.
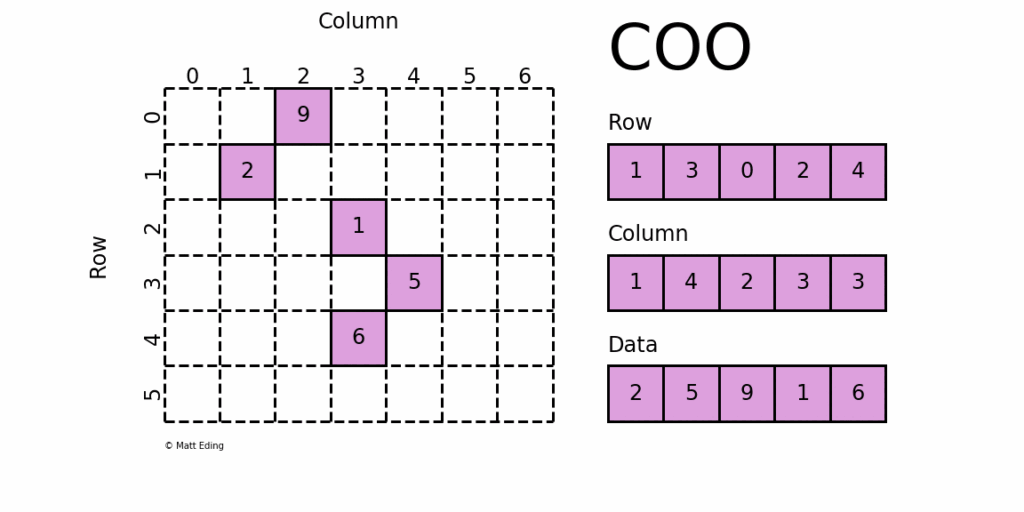
We have 5 non-zero elements, all stored in the data array. They can be in any order, i.e. we do not necessarily have to go row by row through the matrix. The corresponding row and column array stores the index in the matrix itself. So, the first data entry has a value of 2 at [katex]i=1,j=1[/katex], the second entry has a value of 5, which is stored at [katex]i=3,j=4[/katex], etc. This is a simple, yet effective way to store data. And this already gets us a huge improvement over a dense matrix. The issue here is, however, that we are storing both rows and columns explicitly. If we rearrange our data a bit, we actually only have to store the column index.
The compressed sparse row (CSR) matrix
The compressed sparse row (CSR) matrix structure is very similar to the coordinate matrix, but we rearrange our column indices so that they go through row by row. Let's look at an example which hopefully clarifies this situation
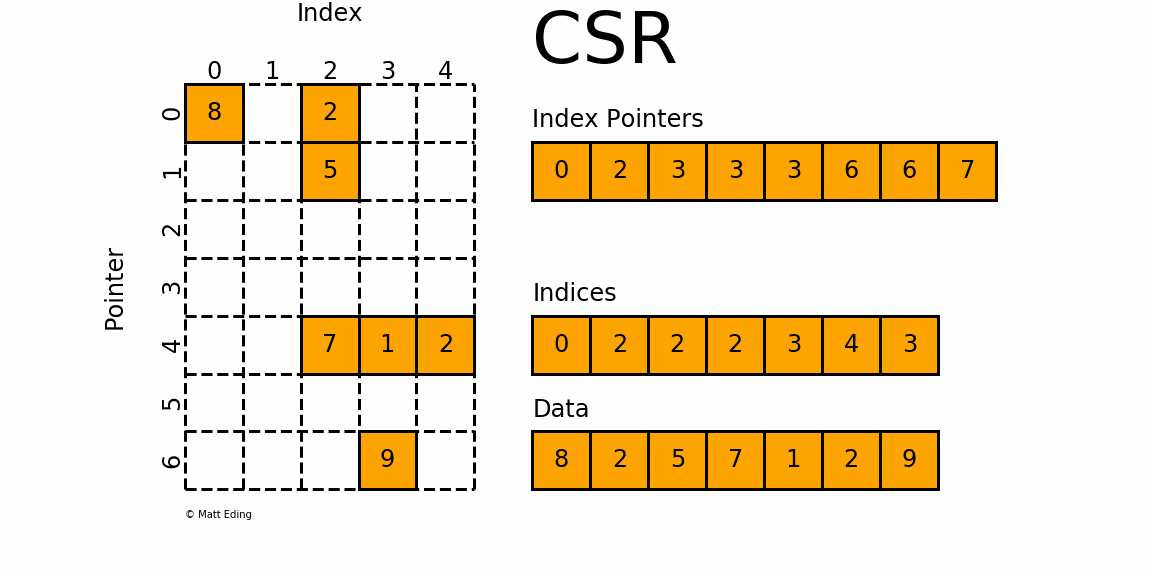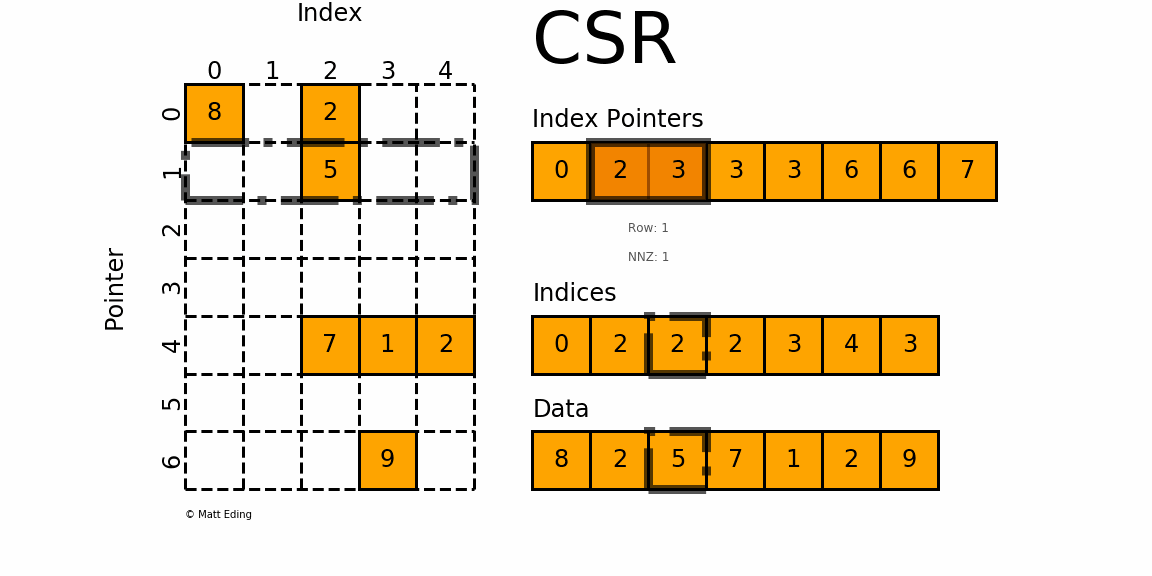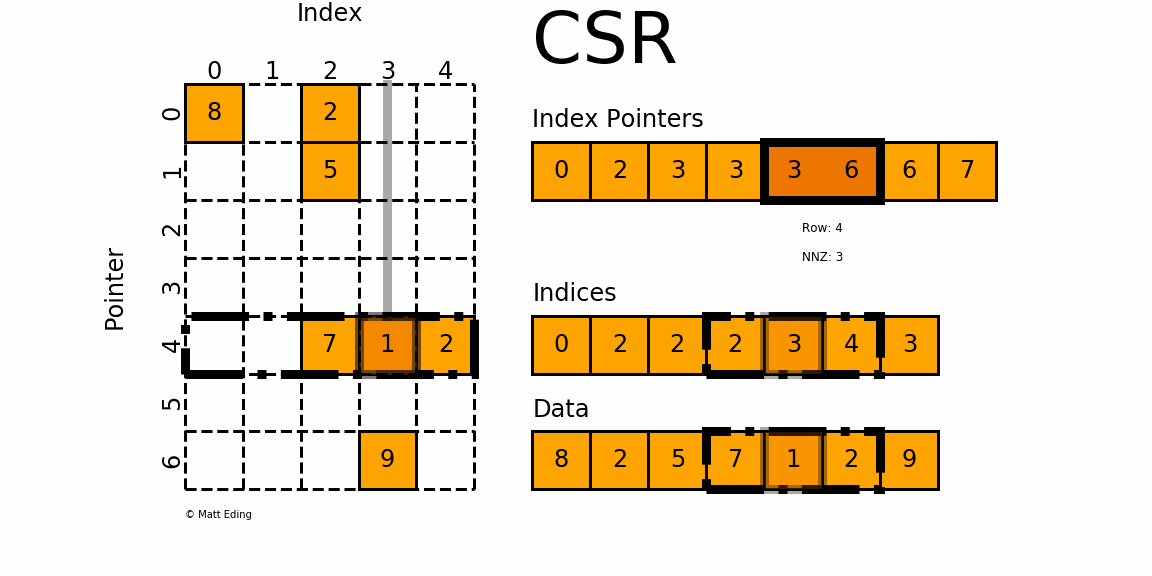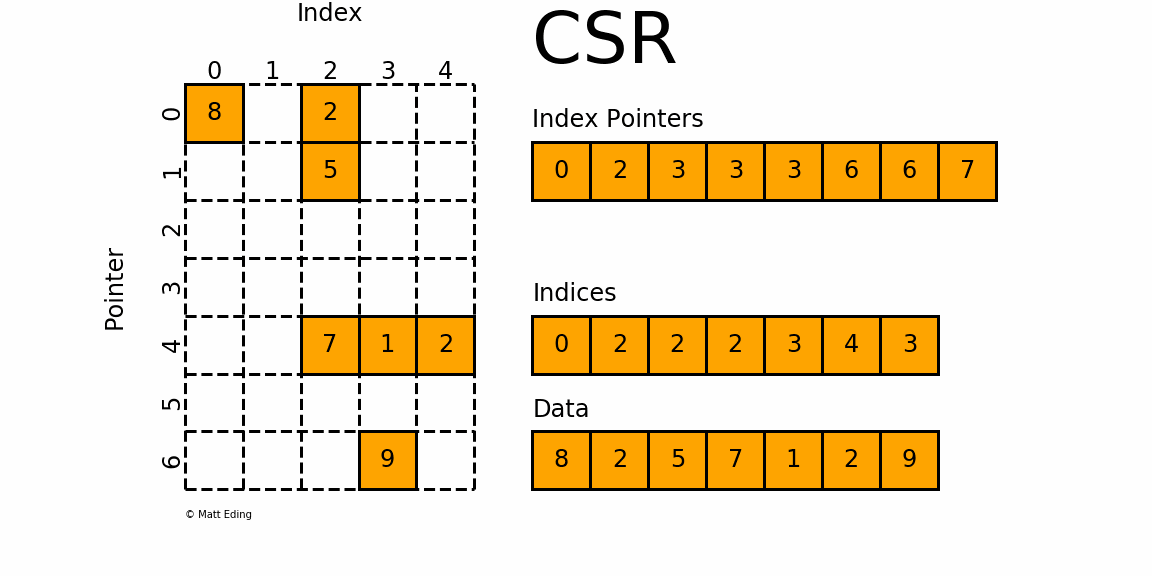
We focus only on the data array and matrix itself for now. The first row has two values; 8 and 2. The data array shows these two values appear as the first two entries as well. The next row contains only a single entry; 5. This is the next entry in the data array. We jump 2 rows and then have another row with values of 7, 1, and 2. These appear next in the data array and finally, on the last row, we have an entry of 9, which is the last entry in the data array. So we see, the entries in the data array are all separated by rows, though we do not know where a new row begins or indeed which column each entry sits in.
For this, we use two additional arrays. First of all, the indices array stores the column location, so for example, the first two entries are 0 and 2, and these correspond to the column location of the first two entries in the data array 8 and 2 (columns 0 and 2). You can see that you can identify the column location for each entry in the data array with this indices array, so it follows that the size of the indices array must be the same as that of the data array.
How do we know in which row the data is stored? For this, we use the index pointer array. Its first value is always 0. The next entry shows how many entries there are for the first row (or rather, how far into the data array we have to index to get to the end of the first row). So in this case, a value of 2 indicates that there are 2 elements in the first row. The next entry in the index pointer array tells us how far we have to go in the data array to get all values in the second row. In this case, the value is 3. Since the previous row stopped at index 2, we have [katex]3-2=1[/katex] entry in the second row.
The next row is more interesting, as we do not have any data here. If we look at the next entry in the index pointer array, its value is also 3, and so it has [katex]3-3=0[/katex] entries! This is the same for the next row, after which the value changes to 6, and so we have [katex]6-3=3[/katex] entries, which correspond to the values 7, 1, and 2 in our sparse matrix.
One important detail is not given, and we have to implicitly construct that information; the current row. The current row is given by the index into the index pointer array. We said the first entry is always zero, but then the next entry at [katex]i=1[/katex] tells us where row 1 ends, [katex]i=2[/katex] tells us where row 2 ends, and so on. So the index into the row pointer array gives us the row, and to obtain all column entries, we have to look at the index pointer array at location [katex]i-1[/katex], which gives us the starting index into our indices and data array, while the index pointer array at [katex]i[/katex] tells us where to stop.
To put this into an example, the first row [katex]i=1[/katex] starts at index pointer [katex]i-1=0[/katex] and goes to [katex]i=1[/katex]. The values in the index pointer array are 0 and 2, respectively. So, we loop over the interval of 0 to 2 in the indices array, which gives us the columns 0 and 2, and then we loop over the data array to get the actual values of 8 and 2. With this information, we can say that we have [katex]A_{0,0}=8[/katex] and [katex]A_{0,2}=2[/katex].
Why do we make our lives so much more difficult? By storing the indices in a row-by-row fashion, we simply have to store where the row terminates, not each row index (which would always be the same as long as we are on the same row, thus storing unnecessary information). As we add more and more neighbours in our computational grid, i.e. as we have more and more entries on a given row, we save storage. From experience, we can say that this not only makes our matrices smaller than a corresponding coordinate matrix but also faster. Sparse matrices can be 2 times faster, potentially more, than coordinate matrices. Since CFD applications spend most of their time solving a linear system, i.e. [katex]\mathbf{Ax}=\mathbf{b}[/katex], we want to make sure it does so as efficiently as possible.
Thus, compressed sparse row (CSR) matrix structures are the one we prefer. For completeness, there is also a compressed sparse column (CRC) structure, but that will lead to more cache misses than the CSR format. Suffice it to say, CSR is probably the most used matrix storage format for CFD applications and this is what we will implement in our matrix class next.
Matrix class interface
After this rather long, but necessary introduction to our matrix class, let's have a look at the class interface then. We'll jump straight into the code and discuss the required functions afterwards.
#pragma once
#include <iostream>
#include <algorithm>
#include <vector>
#include <cassert>
#include "linearAlgebraLib/src/vector.hpp"
namespace linearAlgebraLib {
class SparseMatrixCSR {
public:
SparseMatrixCSR(unsigned rows, unsigned _columns);
void set(unsigned row, unsigned column, double value);
double get(unsigned row, unsigned column) const;
unsigned getNumberOfRows() const;
unsigned getNumberOfColumns() const;
Vector operator*(const Vector& rhs);
friend SparseMatrixCSR operator*(const double &scaleFactor, const SparseMatrixCSR &matrix);
friend std::ostream& operator<<(std::ostream &os, const SparseMatrixCSR &rhs);
private:
std::vector<double> _values;
std::vector<unsigned> _columns;
std::vector<unsigned> _rows;
unsigned _numberOfRows;
unsigned _numberOfColumns;
};
} // namespace linearAlgebraLibThe matrix class structure is actually fairly straightforward and simplistic; we do keep it again to just about the functions we need and no more. We see the usual constructor on line 14, followed by one set and three get functions. The set function allows us to either set or insert new values into our matrix, while the get function gets a value for a given row and column. The next two getters are to query the size of the matrix and then we go into the three remaining operators we require for our Conjugate Gradient algorithm to work.
We saw in our last article on the vector class, that we require a matrix-vector multiplication for the Conjugate Gradient algorithm, this is the function defined on line 22. We also want to be able to scale our matrix with a scaling factor, and, as we saw with our scalar-vector multiplication, we need to define this operation as a friend function if we want to have the order of scalar-matrix multiplication, rather than matrix-scalar multiplication. We discussed this in the vector class article in detail, so we won't dwell on this again here.
Finally, we have the operator<<() again defined on line 24, which we may not use but it helps us print the content of the matrix class.
On lines 27-31, we define a few 1D(!) data structures. To make things clearer, referring back to the image given above on the CSR storage format, the _values array corresponds to the Data array, the _column array corresponds to the Indices array, and the _rows array corresponds to the Index Pointers array, respectively. Let's now turn to the actual implementation.
Matrix class implementation
First, let's define the skeleton of the sparseMatrixCSR.cpp file and then we look into each function implementation individually. The basic structure is given below
#include "linearAlgebraLib/src/sparseMatrixCSR.hpp"
namespace linearAlgebraLib {
// function implementations go here ...
} // namespace linearAlgebraLibAll implementations shown below will be implemented between lines 3-7.
Required class utility functions
The constructor of the class takes the size of the matrix, essentially, and stores that into two private variables.
SparseMatrixCSR::SparseMatrixCSR(unsigned rows, unsigned columns) : _numberOfRows(rows), _numberOfColumns(columns) {
_rows.resize(_numberOfRows + 1, 0.0);
}On line 2, we make use of the fact that the _rows (or Index Pointers, as named above in the CSR storage section) array will always start with 0 and then have _numberOfRows entries, so we can already resize this array to the correct size. For the _data and _column array, we can't know this size in advance.
Next, we have the getters for the size of the matrix and we can query that with the getNumberOfColumns() or getNumberOfRows() functions as shown below.
unsigned SparseMatrixCSR::getNumberOfRows() const {
return _numberOfRows;
}
unsigned SparseMatrixCSR::getNumberOfColumns() const {
return _numberOfColumns;
}The final function I want to look at and classify as a utility function is the operator<<() and the code is given below.
std::ostream& operator<<(std::ostream &os, const SparseMatrixCSR &rhs) {
os << "_Values: ";
for (unsigned i = 0; i < rhs._values.size(); i++) {
os << rhs._values[i] << " ";
}
os << std::endl;
os << "Columns: ";
for (unsigned i = 0; i < rhs._values.size(); i++) {
os << rhs._columns[i] << " ";
}
os << std::endl;
os << "Row Pointers: ";
for (unsigned i = 0; i <= rhs._numberOfRows; i++) {
os << rhs._rows[i] << " ";
}
os << std::endl;
std::vector<double> printVector(rhs._numberOfColumns);
for (unsigned currentRow = 0; currentRow < rhs._numberOfRows; ++currentRow) {
std::fill(printVector.begin(), printVector.end(), 0.0);
for (unsigned columnIndex = rhs._rows[currentRow]; columnIndex < rhs._rows[currentRow + 1]; ++columnIndex) {
auto currentColumn = rhs._columns[columnIndex];
printVector[currentColumn] = rhs._values[columnIndex];
}
for (const auto &value : printVector)
os << value << " ";
os << std::endl;
}
return os;
}There is quite a bit more code to go through here, but it is actually not that complicated. On lines 2-6, we simply print out the content of the _values array. We pretty much repeat the code on lines 8-12 for the _columns array. Since each non-zero entry in the matrix will have a corresponding column index in the _columns array, we can loop over the same length, as indicated by rhs._values.size() on lines 3 and 9. The argument rhs is passed to the function on line 1 and essentially is just the matrix class itself that we want to print.
The row pointer _rows is printed on lines 14-18 and apart from a differently sized array, the code for printing its content is pretty much the same as for the previous two implementations.
Lines 20-30 print the actual matrix. Before we look at the code, though, let's discuss what our goal is here: I want to print the matrix as a 2D matrix, including all zero elements so it looks like a matrix. Since we do not store the zero elements (this is the whole point of the compressed sparse row matrix storage format), we have to construct them now in a row-by-row fashion and then print each row to the console, before moving on to the next row.
So, that is why we first have to define a std::vector of type double on line 20, which, after looping over each row on line 21, is filled with zeros using the std::fill standard template library algorithm. We looked at the standard template library in-depth, feel free to refresh your memory on it and then come back here. On lines 23-26, we simply loop over all column entries (line 23) and then get the value within the matrix on lines 24-25. Once we have put all non-zero elements into this temporary vector (that we call here printVector), we output its content on lines 27-29, and then repeat the whole process for the next row.
Getters and setters
One part of object-orientated programming is that we use getters and setters to access and modify objects (classes). And we are doing exactly that here as well. First, let's look at the get() function, which is slightly easier to understand. It takes two arguments for the row and column and attempts to return the stored value in the matrix at that location.
double SparseMatrixCSR::get(unsigned row, unsigned column) const {
assert(row < _numberOfRows && column < _numberOfColumns && "Invalid row or column index.");
for (unsigned i = _rows[row]; i < _rows[row + 1]; i++) {
if (_columns[i] == column) {
return _values[i];
}
}
return 0.0;
}Similar to functions seen before, we use an assert on line 2 to make sure the right conditions are met before we continue. Then, we loop over all entries in the _columns vector for the given row (again, we use here the indices in the _column array that are between _rows[row] and _rows[row + 1] to limit the indices to only the current row that is given to the function). We check if any of the values stored in the _column vector match the provided column argument to the function on line 5. If it does, then we know that we have a value stored in our sparse matrix and we return that value. If we don't, then we will exit the loop and return the default value of 0 on line 10.
The set() function is a bit more involved. It provides both the row and column index for which we want to set a value, as well as the value itself as the third argument to the function. Let's look through it step-by-step.
void SparseMatrixCSR::set(unsigned row, unsigned column, double value) {
assert(row < _numberOfRows && column < _numberOfColumns && "Invalid row or column index.");
bool rowColumnHasEntry = false;
unsigned index = 0;
for (unsigned i = _rows[row]; i < _rows[row + 1]; i++) {
if (_columns[i] == column) {
index = i;
rowColumnHasEntry = true;
}
}
if (value != 0.0) {
if (rowColumnHasEntry) {
_values[index] = value;
} else {
_values.insert(_values.begin() + _rows[row + 1], value);
_columns.insert(_columns.begin() + _rows[row + 1], column);
for (unsigned i = row + 1; i <= _numberOfRows; i++) {
_rows[i]++;
}
}
}
}After our usual check that the right conditions are met on line 2, we first check on lines 4-11 if we already have a value stored for a given row, column pair. If that is the case, we simply store the index in the _columns array and set the rowColumnHasEntry to true. We then proceed on lines 13-24, where we first check on line 13 if the value that is provided is 0. If it is, there is no point in storing this value, as we are trying to avoid storing any zeros by default.
If the value is not zero, then we have two other conditions to check. The first condition checks if we already have a value stored at the row, column pair. We checked that before, so now we can simply use the rowColumnHasEntry variable to check this, as we do on line 14. If we have, then we simply overwrite the value that we have already stored, and we use the index variable that we have set before, to indicate where in the _values array the current value is stored.
If we do not have an entry already present, then we proceed to lines 16-23. First, we insert the value and the column index at the end of the of the _values and _columns vector. The end here refers to the end of the current row, not the end of the actual vector, and thus we have to find the end of the current row with the offset _values.begin() + _rows[row + 1] and _columns.begin() + _rows[row + 1].
If we add values to our _values and _columns array, then we need to update our _rows array as well, since it stores the start and end locations of each row in these arrays. We don't have to change anything on the rows before, but we need to increase the end location by 1, as we have added 1 column to the current row. This is what we are doing on lines 20-22. We loop over row + 1, because _rows[row + 1] holds the end value for the current row. We loop until the end of the _rows vector and increase each entry by one with _rows[i]++. We could have also written this as _rows[i] = _rows[i] + 1 but I am using a shorthand notation here because C++ let us.
Arithmetic overloaded operators
Finally, let's look at the two operations we need for our matrix class, the matrix-vector and scalar-matrix multiplication.
Scalar-Matrix multiplication
Since we are using a sparse storage format, multiplying our matrix with a scalar becomes incredibly simple. We simply create a copy of our current matrix, and then loop over all entries in the _values array and multiply them by a scaleFactor, which is provided to the function as an argument. We can then return this new matrix from this class. This is shown in the code below.
SparseMatrixCSR operator*(const double &scaleFactor, const SparseMatrixCSR &matrix) {
SparseMatrixCSR temp = matrix;
for (unsigned i = 0; i < matrix._values.size(); ++i) {
temp._values[i] *= scaleFactor;
}
return temp;
}Matrix-Vector multiplication
Before we move on, let's remind ourselves how matrix-vector multiplication works. A matrix-vector operation returns a vector and can be computed in the following way:
\begin{bmatrix}a_1 & a_2 & a_3 \\ a_4 & a_5 & a_6 \\ a_7 & a_8 & a_9\end{bmatrix}\cdot \begin{bmatrix}b_1 \\ b_2 \\ b_3\end{bmatrix} = \begin{bmatrix}a_1b_1+a_2b_2+a_3b_3 \\ a_4b_1+a_5b_2+a_6b_3 \\ a_7b_1+a_8b_2+a_9b_3\end{bmatrix}It is precisely of this operation that the CSR format is so popular and powerful, as we will see next in our code.
Vector SparseMatrixCSR::operator*(const Vector& rhs) {
assert(rhs.size() == _numberOfColumns && "Vector size does not match the number of columns in the matrix.");
Vector result(_numberOfColumns);
for (unsigned row = 0; row < _numberOfRows; ++row) {
for (unsigned columnIndex = _rows[row]; columnIndex < _rows[row + 1]; ++columnIndex) {
auto column = _columns[columnIndex];
result[row] += _values[columnIndex] * rhs[column];
}
}
return result;
}We do our usual check on line 2, in this case, making sure that both the matrix and vector have the correct size to be multiplied together. Then, we create a new vector on line 4 to store the resulting operation in, and then we carry out the matrix-vector multiplication on lines 6-11. We loop over each row, and then for each row, we simply loop over all column indices stored in our sparse matrix. On line 8, we retrieve the actual column index in the matrix, and then we compute essentially the dot product for each row on line 9. We can index our _values vector with the columnIndex, and the right-hand side vector with the column we retrieved from the _columns vector.
If we look at this code, we can see that we can compute each row independently, i.e. there is no need to exchange information between rows. This is excellent news if we want to parallelise our code, as this operation can be turned into a parallel code very efficiently as a result. This is why I mentioned above that the CSR format is so popular with CFD developers.
Summary
This was a somewhat longer write-up but I hope you have gained now the required understanding of why we want to store matrices in a sparse data format in the first place, and secondly, how we actually go about implementing such a sparse matrix with the compressed sparse row (CSR) storage format.
This was a long article with lots of information to digest, so take a breather and try to digest the content in this article. You may want to read up a bit more on sparse matrices to solidify your knowledge in this area, for which some additional references given below may help.
As I have already mentioned, the article by Matt Eding on Sparse Matrices is an excellent introduction. If you want to read more about sparse matrix data storage formats, as well as how to use them in a linear algebra package, I have found the netlib documentation to be excellent. Their HTML-only approach to writing documentation may look outdated, but don't mistake outdated looks over content, the write-up is really good and goes into a lot of depth. They have additional information on the Conjugate Gradient method (and related algorithms), as well as sparse matrix storage formats (not just CSR).
We have now all the pieces together in our library and we can proceed to package our library, as well as compile and test it. We'll do all of that in the next article.

Tom-Robin Teschner is a senior lecturer in computational fluid dynamics and course director for the MSc in computational fluid dynamics and the MSc in aerospace computational engineering at Cranfield University.


