How to manage uncertainty in CFD: the grid convergence index
CFD simulations are riddled with errors and uncertainties that we have to manage as CFD practitioners. The most commonly used technique to establish trust in our simulations is a grid convergence study, where the so-called grid convergence index is calculated. This value provides us with a measure of the mesh-induced uncertainty and, in many cases, is the best line of defence.
However, the grid convergence index has attracted an almost cult-like following and religious belief among CFD users, and this has led to an abuse of this metric, attributing it to some kind of superpowers it does not possess. So, in this article, we will first review common types of errors and uncertainties that exist in every CFD simulation and then narrow down on the grid convergence index and how it can help us to quantify mesh-induced uncertainties.
We will end this article by looking at common misuses of the grid convergence index and how we can spot them. We will also review a Python package and a Chrome browser extension that can help you compute this quantity. If you have never used the grid convergence index in the past, or you have used it without giving it too much thought, then this article is for you.
In this article
- Introduction
- Uncertainties and errors in CFD
- The Grid convergence index (GCI)
- How to calculate the grid convergence index
- Step 1: Calculate the mesh refinement
- Step 2: Calculate the observed order of approximation
- Step 3: Calculate the convergence condition
- Step 4: Calculate the Richardson extrapolated value
- Step 5: Calculate the errors
- Step 6: Calculate the Grid Convergence Index (GCI)
- Step 7: Calculate the asymptotic range
- Step 8: Estimate the optimal number of grid points
- Pitfalls: Avoid these common mistakes
- Refining your grid not uniformly
- Believing the grid convergence index applies equally to structured and unstructured grids
- Refining your grids too little between coarse, medium, and fine grids
- Using single-point measurements instead of integral quantities
- Calculating the grid convergence index because you can
- How to calculate the grid convergence index
- Tools to calculate the grid convergence index
- Summary
Introduction
Mesh generation seems to be a polarising issue in the CFD community. Either you love it, or you hate it (I think I have a flashback; didn't we just talk about polarising software in our last article?! Anyways ...). I find mesh generation to be an almost zen-like meditation; it is very relaxing, and when you get a mesh for a complex geometry but with acceptable quality metrics, it is an incredibly satisfying feeling. But I seem to stand among a group of only a few who share this passion. Most people hate this step, and I don't blame them.
Mesh generation is hard; it is a process entirely driven by the software you are using and the software you are using will dictate the type of mesh you can generate. You have Pointwise, which can generate structured and unstructured grids with standard elements types, but it does not know about polyhedral elements (which I find weird), then you have GridPro, only understanding structured grids.
Ansys Fluent's, StarCCM+'s, Numeca's, and OpenFOAM's meshing algorithms will give you a hex-dominant mesh in the farfield, which is merged through some transitional elements (typically polyhedral elements) towards the inflation layers at boundaries. ConvergeCFD's meshing is rather pleasant, but the support of inflation layers seems to be an afterthought and it does not integrate as well as I have seen in other software.
And then we have the open-source community. Gmsh is commonly stated as a good alternative, though it does not support inflation layers. I am not sure what use a mesh generator is if it can't support inflation layers, but sure, for solids, I can see the appeal of this simple tool. I've heard others talking about Salome as an alternative, but I have never used it. However, looking up some features and capabilities, it certainly can generate inflation layers, and it is probably a software I need to put on my learning list.
So, first, you have to select the right tool to generate a mesh that satisfies your requirements. Next, you have to hope that the algorithms your mesh generator uses are not going to limit you in the future. And then you have to spend a lot of time to become a pro at meshing. So I can see why most people are very happy to throw an automated solution at the problem, hoping to get some kind of grid that will not diverge the simulation.
The output, i.e. the grid that your meshing tool will give you, will be unique. The spacings that you have chosen will determine your mesh and its quality, and if you used the same spacings in another meshing software, you will likely end up with a different mesh. So how do you know if the mesh you have generated is good enough or woefully inadequate? This is what we will discuss in this article, and we will eventually end up with the grid convergence index, which gives us a numerical measure of how suitable our mesh is to capture the quantities we are interested in.
Before we jump into the nitty gritty details, I wanted to highlight the article over at GridPro, where the developers have taken a semi-serious approach to answering the question: Is mesh generation an art or science? I really enjoyed reading this article; I never considered mesh generation to be an art, but I do agree with the points they are making about the art element in mesh generation. In a nutshell, a mesh that looks visually appealing is one that likely has good quality, and the opposite is true for poor-quality grids as well.
However, there is a hard science behind mesh generation as well. Things like the spacing of the first element based on your y+ requirements is hardly an art, but rooted in sound physical principles. The same is true of determining mesh-induced uncertainties with the grid convergence index (GCI), but we are getting ahead of ourselves. Let us first have a quick review of uncertainties and errors that we have to battle with in CFD and then look at how the grid convergence index (GCI) can lift some of that uncertainty (or, at least, quantify it).
Uncertainties and errors in CFD
A common misconception novice CFD users have is that CFD is an exact science. This misunderstanding is entirely understandable, after all, we solve the Navier-Stokes equations in CFD and if you see the derivation of these equations (as you most likely will if you take an introductory course on CFD), you will get a sense of mathematical elegance and preciseness, and may thing that this also translates to the rest of the CFD workflow. Nothing could be further from the truth.
If we want to have an analogy, think of a bird. Let's say that the ease and elegance birds have when flying through the air is akin to the elegance we see in deriving the Navier-Stokes equations. On the other hand, solving the Navier-Stokes equations with CFD would be equivalent to a rock thrown into the air. Sure, it'll fly, at least for a bit, before it crashes.
CFD is full of uncertainties and errors, and what separates a good CFD practitioner from someone that knows how to press the right buttons based on watching a few YouTube tutorials is that a good practitioner is able to manage, and in some cases quantify, uncertainties and errors. A central part to this discussion is the grid convergence index (GCI) that we will look at in this article.
But before we do, let us review typical sources of uncertainties and errors in CFD. On this topic, my favourite book for verification and validation purposes is the one by Oberkampf, which you can find on my reading list as well. It is well worth a read if you are just starting out with CFD or a seasoned practitioner and want to get a more in-depth understanding of uncertainty management. But with that out of the way, let us have a look at sources of uncertainties and errors next.
Sources of uncertainty in CFD modelling
The grid convergence index is just one method of many to quantify and manage uncertainties. But there are other types of uncertainties and errors that we need to be aware of at least, to have a feeling for how good, or bad, our simulation results are. The more we can discuss our results in light of known limitations, the better we can cmmunicate the usefulness of our results.
We should keep in mind that all CFD simulations will be limited. Running a steady-state RANS simulation to extract an acoustic signal for noise predictions is useless. Even switching to an unsteady RANS (URANS) approach will not resolve the small-scale turbulent features we need to get an accurate reading of the acoustic footprint. You may run an incompressible DES or LES simulation, but even then, you may get challenged if you were, for example, to use an incompressible description with a constant density assumption.
The models, schemes, algorithms, and boundary conditions we use to set up our simulations will determine the information we can extract. Even if we model our flow correctly to extract an acoustic signal, we still have to combat uncertainties and modelling errors that may or may not influence our results. It is our job to convince who ever is interested in our results that the level or uncertainties and errors is so low that it would not change the main conclusions if we were to get rid of them entirely.
If we can demonstrate that, we gain trust, and people will believe our results, and you will gain credibility as a CFD practitioner. As it turns out, one of the largest uncertainties we have to manage is the influence of the grid on our results. A coarse grid will give potentially less accurate results than a fine grid, but the reverse can be true as well!
Refining a grid beyond a point where any more accuracy may be achieved can lead to non-physical results. Think of a grid which is refined to a point where we resolve the smallest of turbulent features. If we use a RANS model, it can't predict these features, but it will give you something. All that it is doing is injecting your simulations with features that are non-physical, and these may result in convergence never being reached.
Or, you may resolve a multiphase flow where you are modelling particles based on an Eulerian description (i.e. you don't resolve the particles themselves but rather compute how much of the particle is within a computational cell and then you transform that information into a volume fraction). If your cells are now getting smaller than a particle, then it is possible to get volume fractions of more than 100%, leading to divergence.
So, let us review some uncertainties and errors and keep them in mind for when we analyse our simulations. As alluded to above, we will be looking at the grid convergence index (GCI) as one method to quantify the biggest uncertainty we have, i.e. grid-induced uncertainties.
Measurement uncertainty
The first uncertainty that we have is measurement uncertainty, which is true for both CFD and experimental results. The following figure represents the issues with measurements, where we take repeated measurements to predict the centre of a circle:

There are two types of measurement uncertainty: Precision and accuracy.
- Precision: A repeated measurement will result in a value that is close to other measurements
- Accuracy: Taking an average over all measurements will result in an accurate prediction of the quantity we are measuring.
Let's make this more real by measuring the lift and drag force coefficients of an airfoil. Let's say we run an experiment and measure the lift and drag coefficient every second for a total duration of 10 minutes. A precise measurement would be one where we see a small standard deviation, or variance, while an accurate measurement would be one in which we see a mean lift and drag coefficient that is closely matched with an expected value, for example, a lift value of zero for a symmetric airfoil at an angle of attack of zero.
Let's look at how this concept can be translated to CFD measurement uncertainties. The following graph shows the development of the drag coefficient for a steady-state RANS simulation:
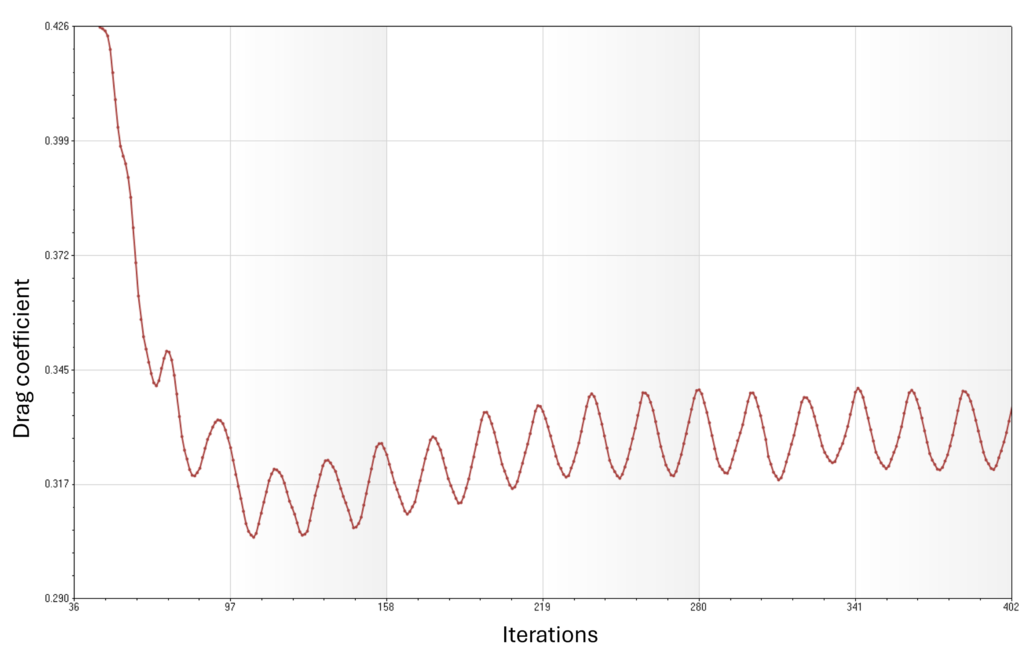
Let's say the solution has converged at around 280 iterations. What is the corresponding drag value at the end of the simulation (at 402 iterations)? The drag value oscillates between 0.32 and 0.34, and if we were just to take the value at the last iteration, we would get some value in this interval, but is it an accurate value? We can probably all agree that taking an average drag coefficient over a number of iterations, say, 150 or so, would probably give us a more accurate reading of the true drag coefficient.
What about the precision? if we now simulated the case with a different turbulence model, we would, perhaps, get a drag coefficient oscillating between 0.29 and 0.37. Sure, the mean drag coefficient would still be similar to the one obtained from the above graph, but how much confidence would we have in the value given the higher level of oscillations?
This may also seem trivial and obvious, but believe me, it is very common for people to run steady-state RANS simulations and then believe that the results they are seeing are steady-state, so they can just take integral quantities like the lift and drag coefficient at the last iteration. We also would typically plot contour plots for the last iteration only, but even those are likely clouded by some oscillatory behavior and we ideally should also look at some averaged flow properties, even if we use a steady state description.
Mesh-induced uncertainty
This discussion is a precursor for the grid dependency index that we will look at shortly, but let's look at this from a high level first. If we generate three different grids, by subsequently refining our grids so that we have a coarse, a medium, and a fine grid, each having a larger number of cells than the previous one, we would expect that our results get more accurate as we refine our grids. This is wrong.
When we refine our grids, the accuracy does not improve; instead, the precision will improve. Put differently, if we are interested in measuring the lift and drag coefficient in a simulation, then the uncertainty of this measurement will be reduced. We may get really good results on a coarse grid, which are not significantly different from the medium or fine grid solution, but we have less certainty that the solution is as good as on the medium or fine grid. Let's look at this statement more closely by inspecting the following figure:
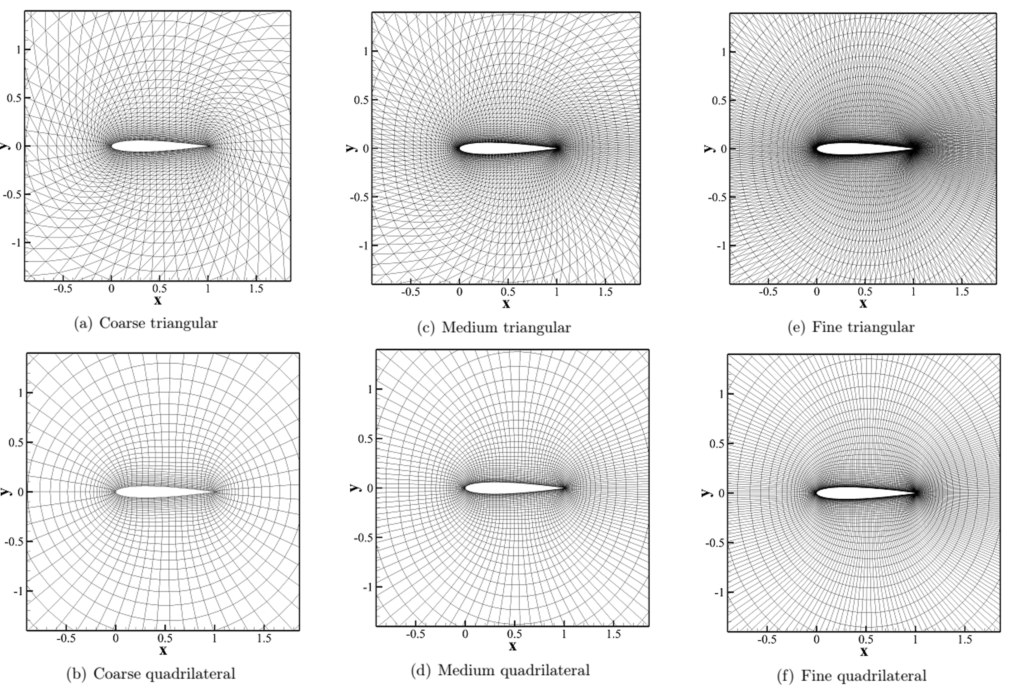
Here, we provide a coarse, medium, and fine grid for the flow around an airfoil for both an unstructured (top) and structured (bottom) grid. Let's stick with the example of measuring the lift and drag coefficient, and let's also assume that we are investigating transonic flows, i.e. one in which shock waves are emerging. How well would we expect our drag coefficient to be captured with these grids? Probably not that well, as we are not providing any mesh refinement in areas where we would expect shock waves to form, which are important to determine the wave drag of the airfoil.
So, it is not enough to just provide mesh refinement; it needs to be systematic, and we need to refine the mesh in areas that are responsible for capturing the quantities or flow patterns that we want to study. In our case, we want to capture the drag, which requires a good resolution near the wall with inflation layers to capture the velocity gradient accurately, which in turn captures the profile drag. We also need some refinement on the top and bottom of the grid to capture any emerging shock waves.
If this we solved this case in 3D, then we also want to resolve wingtip vortices and wake to capture induced drag. Furthermore, if we are interested in simulating high angles of attack, we will get a separation point on the upper airfoil surface, either due viscous boundary layer separation or through shock wave boundary layer interactions (SWBLI).
But even if we refine the mesh in areas we expect to be important, why are we only improving precision and not improving accuracy (necessarily)? Well, the solution you obtain is just that, a solution to the underlying partial differential equation (the Navier-Stokes equations) that you are solving. To get a solution, we have to provide boundary conditions and initial values, and the solution of any (partial) differential equation will depend on either the boundary or initial conditions, or both.
While the initial condition typically only influences the length it takes for your simulation to converge (though I have experienced cases where different initial conditions can be the difference between convergence and divergence), the boundary conditions dominate the solution of your problem. If we run the simulation with an inlet velocity of, say, [katex]100 m/s[/katex] or [katex]1000 m/s[/katex] (i.e. a Mach number of approximately 0.3 or 3.0 at standard atmospheric conditions), then we would expect to get a rather different solution.
So, if we provide the wrong boundary conditions, then it does not matter how much our mesh is refined, we will get a wrong result. In this case, this is a simple fix, i.e. if we made a typo in the boundary condition set up, we can spot and fix it, but there are other, more challenging cases, where boundary conditions are limited and not able to resolve the flow properly.
For steady state RANS, a typically problem is reverse flow at outlets. Sometimes we can move the outlets further away to avoid this, but if that is not possible, the we have to handle the reverse flow issue. Sani and Gresho held a minisymposium on exactly this issue and came to the conclusion that all proposed outlet boundary conditions are violating physics, and they were unable to provide a satisfactory solution. We still use the same outlet boundary conditions they investigated nowadays, despite the study being conducted in the 1990s.
Furthermore, most of the time, we do not solve the Navier-Stokes equations; rather, we solve a closely related equation. After all, RANS stands for Reynolds-averaged Navier-Stokes, which is not the Navier-Stokes equation (but instead a time-averaged form of it). While there is nothing wrong with the RANS equations themselves, they are not solvable, and we have to come up with models (RANS turbulence models) that provide estimates here.
This means we are no longer solving the exact Navier-Stokes equations, and our simulation's convergence and results will depend on the turbulence model. If we change the RANS model, we'll likely get a different result for, say, the drag coefficient. Thus, the combined effect of the boundary conditions and turbulence model (plus any other model that we may use in our simulation) largely determines the accuracy of our simulation; the mesh refinement will only improve the precision of the results these combined models and boundary conditions provide.
However, if we make the right assumptions and feel comfortable that the selection of numerical schemes, algorithms, turbulence models, boundary conditions, etc., are a good fit for the problem that we want to solve, and we know the areas in the mesh we need to refine to get a more precise measurement for our quantities of interest, then mesh refinement will likely get us more accurate results. However, mesh refinement by itself is not a guarantee of better accuracy.
Iterative uncertainty
This is another good one. One of the more common misconceptions I have to debunk in my students is that the residuals don't tell you anything about convergence! The only thing you can read off from the residuals is whether your solution is diverging, converging, or plateauing, potentially oscillating around a mean residual value. With relatively simple measures, you can artificially construct a case where you get a converged but incorrect solution and one where you don't get convergence but a correct solution.
The following plot shows the convergence history for the lid driven cavity problem, which is the flow inside a quare box in which the top boundary is moving from the left to the right, inducing a vortex at the centre.
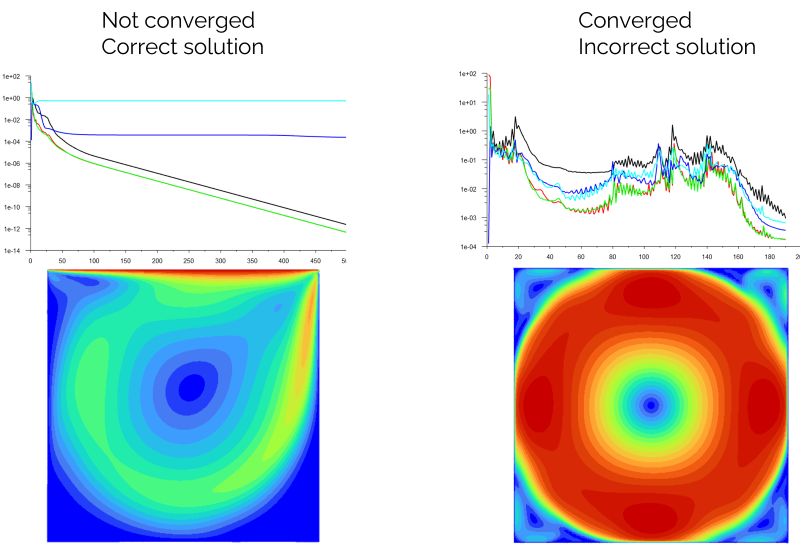
On the left, we see the correct behaviour, where the main vortex forms. The residuals, however, plateau and do not get below a convergence threshold. On the right, we see an incorrect behaviour, but the residuals have converged to the relatively modest convergence threshold of 1e-3.
Residuals do not equal convergence, even if the residuals have dropped below a convergence threshold! Granted, the example above is extreme, and not likely to repeat itself in real situations often, but it just shows the danger of using residuals to judge convergence.
The reason many still use residuals to judge convergence is based on how they are computed. Residuals simply measure the difference in the solution from one iteration to the next. If our solution does not change significantly, then we expect low residuals and, thus, a converged result. This works in theory, but in practice, we make so many assumptions that will result in poor convergence, and thus, plateauing of residuals is the norm, not the exception, especially for high Reynolds number flows.
If you still don't believe me, here is an experiment you can try at home. Initialise the flow with a wild guess, it doesn't matter what it is, the further from the real, physical solution, the better (i.e. initialise the flow with a constant negative flow which goes against the inlet velocity component, for example). Now set the under-relaxation factors to 1e-10 for all quantities. Set your convergence threshold to 1e-3, though you can go lower if you want (it doesn't really matter).
Despite having an objectively bad initial solution, you will see that your residuals converge within one iteration. The solution you will see is wrong, but the residuals will reliably drop below your convergence threshold of 1e-3. Why? Under-relaxation will limit how much the solution can change from one iteration to the next, and if we multiply all changes by 1e-10, then the actual changes in our solution will be small, resulting in a small residual being calculated.
So how can we get around this issue? Ignore residual-based convergence checking and, instead, introduce quantities that you are actually interested in extracting from your simulation, like the lift and drag coefficient, for example. Calculate how much these quantities are changing between iterations, and use that instead as a measure for convergence.
Whatever you do, please stop using the residuals as your only measure for convergence!
Sources of errors in CFD modelling
Having looked at the two biggest uncertainties that will plague you in your quest to get accurate CFD results, let's turn our attention to the most common sources of errors. Some of them we can influence, some we can't, and sometimes we won't even have a chance to quantify or even just get a feel for how large this error is. This is where experience, testing, verification and validation come into play, and we will need to build up our experience to ensure that our results are a true reflection of reality and not a construct of the accumulated errors of our simulation.
Numerical scheme errors
Our numerical schemes that we use to approximate gradients (finite difference) or interpolate values from cell centers to cell faces (finite volume), have a nominal order of approximation. Let's stick with the finite volume approach for the moment, and let's consider a first-order and second-order upwind scheme, where the nominal order of approximation is 1 and 2, respectively.
In the first-order case, we simply copy values from cell centres to cell faces. This means that we assume there is no change within each cell, and as we go from cell to cell, we have a discontinuous change at the cells' faces. In the second-order case, we do something similar, except that we take the local gradient of the quantity we are approximating into account. However, this may still lead to discontinuities. Both the first- and second-order upwind schemes are schematically shown in the following figure:
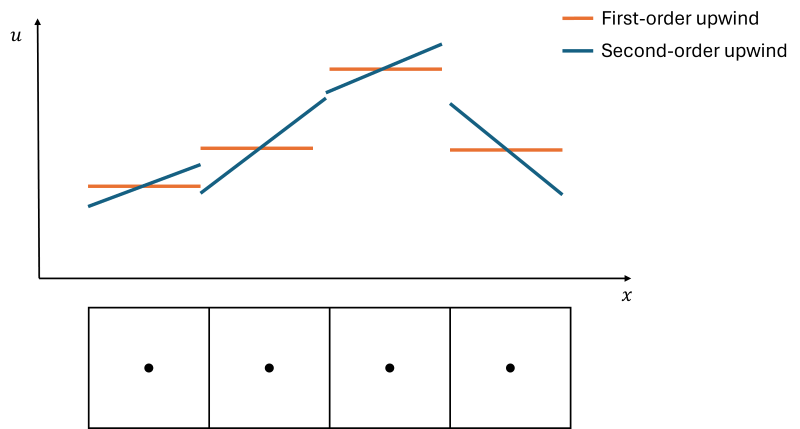
Here, an arrangement of cells is shown at the bottom, and we can see how the solution is assumed constant across cells in the first-order scheme while variation is allowed in the second-order scheme. If the signal (in this case, [katex]u[/katex]) is smooth, then we get small discontinuous changes going from cell to cell, but in the case of compressible flows, we may get shock waves, where these changes get larger.
These discontinuities only arise as the numerical schemes make certain assumptions, i.e. the first-order upwind scheme assumes the signal is constant, while the second-order upwind scheme assumes the flow to be linearly changing. The flow may be approximated well with a scheme that assumes linear changes only if the cells are rather small, but in reality, the flow may change with a polynomial behaviour, and our assumption of linear change in the flow property will be wrong.
Thus, numerical schemes introduce an approximation error that diminishes as we refine the grid, but it will always be there. The nominal order of approximation tells us how quickly this error diminishes. Say you have a simple case in which you know the behaviour of the flow analytically. Then, you can compute the error between your solution and the analytic solution.
A first-order scheme will reduce the error by a factor of 2 as we double our mesh size. A second-order scheme will reduce the error by a factor of 4. If we put this into an example, say we solve a 1D flow and have 100 grid points and a computed error of 0.5, then on a grid with 200 grid points, we expect the error to be 0.25 with a first-order upwind scheme and 0.125 with a second-order upwind scheme. The error drops with [katex]2^p[/katex], where [katex]p[/katex] is the nominal order of approximation (1 or 2 in our case).
You may then conclude that we should always be using higher-order schemes, i.e. those with high orders of approximation, but these bring about different problems; there is no free lunch. Higher-order methods introduce oscillatory behaviour and can reduce accuracy, especially near discontinuities. There are ways around that (using a so-called limiter), which in turn will influence your convergence rate.
Ultimately, we hope that by refining the mesh sufficiently and obtaining results where quantities of interest do not change significantly (like the lift and drag coefficient), that the numerical scheme error has reduced to a level where it does not manifest itself in the solution. The best protection we have here is to compare our results against analytic solutions and, in the absence of them, experimental data.
But don't assume that experimental data is free of errors either, we might be getting far better results than what the experiment can measure. Or we may be able to reproduce a certain geometry with much more detail than a wind tunnel model. You because your results do not match with the experimental results does not mean that your results are flawed. You have to exercise your critical thinking here and make a judgement on which results are correct and why. However, experimental data will give us confidence if we have a close match.
Physical modelling errors
This error pertains to errors made in our models that model some part of the physics we are not resolving, and that is largely the turbulence models we use. For Stokes flow (i.e. low Reynolds number flows), that we may find in microfluidic applications, the Navier-Stokes equations are dominated by viscous effects (diffusion), rather than convective effects (non-linear term). Since there is no turbulence and the flow can be considered to be laminar, we can get pretty accurate results, as no turbulence model is required. Furthermore, diffusion can be well captured with linear numerical schemes.
However, for large Reynolds numbers, we need to face the challenge of turbulence and as the saying goes, all models are wrong, only some turn out to be useful (but not correct). This is true for turbulence models and we have already alluded to their influence above when discussing the mesh-induced uncertainties.
But any other model that we introduce will equally influence the accuracy of our simulation, be it a Riemann solver which linearises the flow or a multiphase model where different methods exist to track the interface between two phases, each model will make assumptions that may or may may may not be correct for your simulation. Only experience, expertise, and testing will allow you to investigate how useful these models are for your type of application, which typically requires a systematic study of different models and their parameters in the absence of best practices.
Programming errors
No software is free of software defects/regressions/bugs. Period. If you assume that you pay ANSYS, Siemens, or any other large commercial CFD solver vendor a small fortune to use their well-tested and bug-free CFD solver, you are mistaken. Each solver has their own bugs. Sometimes, these can be as insignificant as breaking the graphical user interface, and they can become more serious when some internal scheme or algorithm is not implemented correctly. We have no way of knowing unless we can inspect the code.
The best way we have to protect ourselves against programming errors is a to follow good software testing practices; that is, writing unit, integration, and system tests for our solver as we develop it. This ensures that we have confidence in the correct working behaviour of critical parts in our solver, and I have an entire series on how to systematically implement a rigorous software testing practice in CFD software. It is that important.
Other than being able to inspect the source code, we have no way of telling if the code is correct or not. We may not have any control over the software testing practices used by the developers of the CFD solver we are using, but we can make our own validation and verification studies to ensure the solver is working correctly.
Usage errors
Simply put, if we use the CFD solver incorrectly, then it is our fault for getting the wrong results. We may have a CFD solver that is perfectly capable of giving us correct results, but if we can't set up a simulation correctly, then it is our usage error that will prevent us from getting correct results, with no blame on the solver for once.
OpenFOAM is an excellent example of this, where even a PhD degree in CFD will not fully prepare you for all of the different options you can and have to set in the set-up files. A decision to learn OpenFOAM is akin to a marriage proposal, i.e. this is a long-term commitment (and, like marriage, I suspect that every second person is giving up on the software ...).
Post-processing errors
This is an interesting one. We may have used the perfect solver, have done the set up of our simulation without any user errors, and gotten perfect results. However, now we throw it into a post-processing software like Tecplot and Paraview, and well, you guessed it, these are software as well, so they, too, can be plagued with bugs that may lead to incorrect interpretation of results.
I once had to work on visualising the results from a higher-order numerical simulation using the discontinuous Galerkin method, and my supervisor and I were looking at the results in Tecplot and were suspicious of the contour plots. There was a discontinuity that shouldn't have been there, but it was exactly on the interface between two different grid zones (where we switched from tetrahedra to hexahedra elements). We weren't sure if this was an interpolation error on the graphics side (OpenGL) or an incorrect implementation on my behalf.
Most of the time, we can probably believe the results, but every now and then, we may need to question the validity of what we are seeing and identify where the error is coming from (i.e. the post-processor itself or your code). In case you are wondering, my implementation was wrong, and Tecplot was right.
The Grid convergence index (GCI)
Having reviewed the most common types of uncertainties and errors that we have in our simulations, I want to turn our attention now to the grid convergence index, which is the best way to mitigate most of these issues. The grid convergence index, or GCI, will give us a numerical value (in percent) for how much uncertainty there is in our mesh. To obtain this grid convergence index, we need to run a series of simulations on three separate grids, which all have a different number of cells. We label these grids, as we saw before, the coarse, medium, and fine grids.
Ideally, we want the grid convergence index to be as low as possible, but we know that increasing the mesh size will increase the computational cost, the in reality, we aim for a grid convergence index beyond which we see diminishing returns on our (computational time) investment, and there is a way to judge that, again, with a numerical value. We will see that in a second as well.
So, there are only two things we need to perform a grid dependency study
- A series of 3 grids with a coarse, medium and fine resolution, where each grid has more cells than the previous grid.
- We can measure a single quantity on all grids, such as the lift or drag coefficient.
We can have more than a single quantity; for example, we could look at the lift and drag coefficient, as well as the pressure drop, and then calculate the grid convergence index for all three quantities. All of them may return a different grid convergence index, which means that there are different levels of uncertainties to obtain different quantities. Thus, once we have established the mesh-induced uncertainty for one quantity, it does not mean that this is the global uncertainty for the grid, only for the quantity of interest.
The way that the grid convergence index works, in a nutshell, is to check how much the solution is changing as we go from the coarse to medium and from the medium to the fine grid. Then, we can calculate the differences between our integral quantities, like the lift and drag coefficient, from one grid level to the next, which we call the error. Perhaps this is not the best terminology, but the argumentation is that once we have reached sufficient mesh refinement, the quantities of interest will no longer change as we refine the mesh, resulting in an error of zero (or close to zero).
Furthermore, we know the refinement ratio between grids, and we can calculate the observed order of approximation of our numerical schemes. Even if our nominal order of approximation is, say, 2, because we are using a second-order accurate scheme, the actual, or observed order of approximation may be lower, typically due to unstructured grid properties (but other factors can also play a role here).
With the refinement ratio, the order of approximation, and the error in our quantities of interest, we can throw all of them into an equation to get an uncertainty that remains in the grid. As we have discussed above in the section on numerical scheme errors, we have a certain expectation of how much the error (or, here, the difference between solutions) will decrease as we increase the number of cells. We use this knowledge to construct the grid convergence index, and any deviation from our expectation by how much the error ought to be reduced is due to mesh-induced uncertainty.
Let us now go through the steps required to calculate the grid convergence index.
How to calculate the grid convergence index
There are a few different ways to calculate the grid convergence index (and they mainly differ in how the observed order of convergence is calculated). There is a good discussion of how the grid convergence index is derived on NASA's website (which I will skip here as I want to concentrate on the correct usage, but I have heard good things about these NASA guys, apparently they can predict the future of CFD). The derivation I'll follow is that of Celik et al., which is likely the most widely accepted form of the grid convergence index nowadays.
This involves 7 steps, which we will go through in the following.
Step 1: Calculate the mesh refinement
The first thing we want to establish is the refinement ratio between different grid levels. However, it is not as simple as taking the number of cells of two separate grid levels and then using this number as the mesh refinement ratio. To see this point, imagine decreasing the spacing of the cells by a factor of 2 for a 1D, 2D, and 3D simulation. In the 1D case, we are doubling the number of cells, in a 2D case, we are increasing the number of cells by a factor of 4, and for 3D, we increase it by a factor of 8. However, this is only true for Cartesian grids, and it would not work for unstructured grids.
Thus, the first thing we do is to calculate a representative grid spacing, which we will denote [katex]h[/katex]. This can be achieved for 1D, 2D, and 3D cases in the following way:
- 1D:
h=\left[\frac{1}{N}\sum_{i=1}^N \Delta x_i\right]- 2D:
h=\left[\frac{1}{N}\sum_{i=1}^N \Delta A_i\right]^{1/2}- 3D:
h=\left[\frac{1}{N}\sum_{i=1}^N \Delta V_i\right]^{1/3}Here, [katex]\Delta x_i[/katex], [katex]\Delta A_i[/katex], [katex]\Delta V_i[/katex] are the cell spacing, cell area, and cell volume in 1D, 2D, and 3D, respectively. By taking the square and cube root in 2D and 3D, respectively, we ensure that we get a sort of average or representative spacing for each cell. Then, we simply take the mean of all representative cell spacings, which will give us an equivalent 1D spacing, which we can now use to calculate the refinement ratio.
We follow the convention of abbreviating the coarse, medium, and fine grid with the following indices:
- 1: Fine grid
- 2: Medium grid
- 3: Coarse grid
This, if we wanted to calculate the refinement ratio as [katex]r[/katex], as we go from the medium to the fine grid, we could express that as [katex]r_{medium, fine}[/katex], which is commonly abbreviated to [katex]r_{21}[/katex]. Similarly, we can introduce the refinement ratio from the coarse to medium grid as [katex]r_{32}[/katex]. These are then calculated as
- Coarse to medium grid:
r_{coarse, medium}=\frac{h_{coarse}}{h_{medium}}\quad\rightarrow\quad r_{32}=\frac{h_3}{h_2}- Medium to fine grid:
r_{medium, fine}=\frac{h_{medium}}{h_{fine}}\quad\rightarrow\quad r_{21}=\frac{h_2}{h_1}Step 2: Calculate the observed order of approximation
In the next step, we want to obtain the observed order of approximation. We could simply set this to the nominal order of the approximation, i.e. use [katex]p=1[/katex] for a first-order scheme and [katex]p=2[/katex] for a second-order scheme, but calculating it will give us a better feeling for the actual order achieved int he simulation. It also provides us with some protection against unrealistic grid convergence index results; if [katex]p[/katex] takes on unrealistic values, there may be something wrong with our calculation, see common pitfalls in the next section of this article.
The observed order of approximation, sometimes also referred to as the order of convergence or apparent order of convergence (mainly by me, as I am consistently inconsistent), has to be approximated iteratively. We start by assuming a value for [katex]p[/katex] (it doesn't really matter which value, typically 1 and 2 will do), and then we refine this guess based on the following iterative equations:
\begin{aligned}
p&=\frac{1}{\mathrm{ln}(r_{21})}\left|\mathrm{ln}\left(\frac{\phi_3-\phi_2}{\phi_2-\phi_1}\right)\right| +\left|\mathrm{ln}\left(\frac{r_{21}^p-s}{r_{32}^p-s}\right)\right|, \\
s&=sign\left(\frac{\phi_3-\phi_2}{\phi_2-\phi_1}\right).
\end{aligned}Here, the [katex]sign()[/katex] function will return the sign of the argument provided, i.e. [katex]+1[/katex], [katex]-1[/katex], or [katex]0[/katex]. The values of [katex]\phi_1[/katex], [katex]\phi_2[/katex], and [katex]\phi_3[/katex] represent the solution of our quantity of interest on the fine, medium, and coarse grid, respectively. I.e. we can have [katex]\phi=cl[/katex] for the lift coefficient, or [katex]\phi=cd[/katex] for the drag coefficient, and so on.
An implementation of this iterative procedure is shown in the following Python code:
def __find_apparent_order_iteratively(self, e21, e32, r21, r32):
eps = 1
iteration = 1
max_iteration = 100
norm = 1
p = 2
while eps > 1e-6:
p_old = p
s = self.__sign(e32 / e21)
q = log((pow(r21, p) - s) / (pow(r32, p) - s))
p = (1.0 / log(r21)) * fabs(log(fabs(e32 / e21)) + q)
residual = p - p_old
if iteration == 1:
norm = residual
iteration += 1
eps = residual / norm
if iteration == max_iteration:
print('WARNING: max number of iterations reached for calculating apparent order p ...')
break
return p
def __sign(self, value):
if value == 0:
return 0
elif value > 0:
return 1
elif value < 0:
return 0Step 3: Calculate the convergence condition
The convergence condition tells us if our quantity of interest is either converging or diverging and if this converging/diverging behaviour is happening monotonically or oscillatory as we increase the number of cells in the mesh. Take a look at the following schematic:
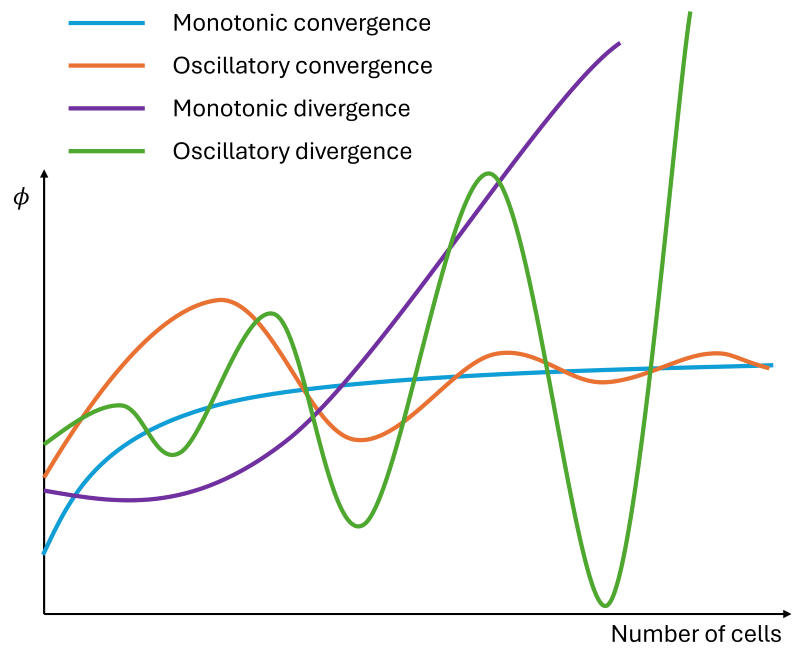
In this case, we can see that monotonic convergence (blue line) results in what we hope to observe in all cases, i.e. the difference in our quantity of interest decreases as we increase the mesh size. However, it is possible to observe a more oscillatory behaviour, as seen by the orange curve, which is labelled oscillatory convergence. In either case, both solutions indicate a convergence towards a specific value.
The pruble and green lines, on the other hand, represent monotonic and oscillatory divergence. Either case indicates that the solution is not converging but instead diverging. If you observe either condition, you will have to go back to your meshing software and start from scratch. Something went wrong here, and you are observing divergence, usually due to poor grid quality metrics (though you may be resolving additional flow features that may change the flow as you increase the mesh size, which can also lead to divergence).
The convergence ratio is calculated as:
CR=\frac{\phi_2-\phi_1}{\phi_3-\phi_2}We then compare the computed value of [katex]CR[/katex] against the following conditions:
- [katex]CR < -1[/katex]: Oscillatory divergence
- [katex]-1 \le CR < 0[/katex]: Oscillatory convergence
- [katex]0 \le CR < 1[/katex]: Monotonic convergence
- [katex]CR \ge 0[/katex]: Monotonic divergence
You should always aim for monotonic convergence if you can, but sometimes you may see oscillatory convergence as well (see also common pitfalls below, where we look at one such example, i.e. uniform vs. non-uniform mesh refinement). If you observe divergence, you grid dependency study is telling you that you need to start over. Your results are not grid-indipendent, in fact, it is the opposite, so go back to the drawing board and try again.
Step 4: Calculate the Richardson extrapolated value
So, we stated that as we reduce the mesh-induced uncertainty, our precision would increase. This increase in precision means that if we take measurements of a quantity of interest on grids with an ever-increasing number of cells, we will eventually end up with a precise measure that does not change very much. However, we do not have to refine our grids indefinitely; instead, we can use the Richardson extrapolation, which will take a best guess as to what our quantity of interest ought to be on a grid that is free of mesh-induced uncertainties.
This is shown in the following figure, where the quantity of interest is shown here as [katex]\phi[/katex] and how it changes with an increase in the number of cells in the mesh. At some point, we only get small changes, and as we increase the mesh size, we will asymptotically approach the red line, which represents a precise measurement of our quantity of interest.
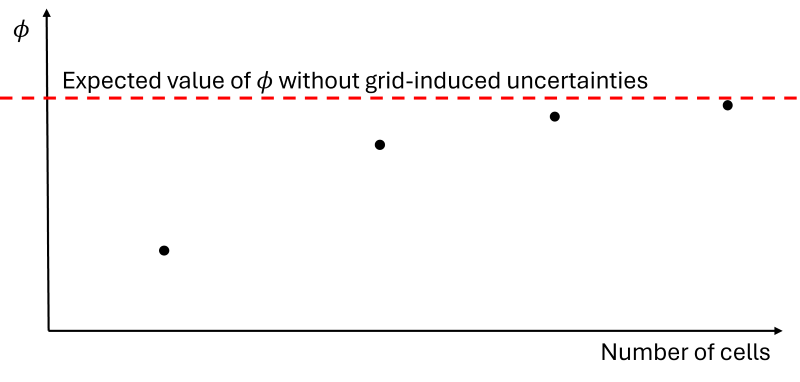
The Richardson extrapolation can be calculated based on
\phi_{extrapolated}=r_{21}^p\frac{\phi_1-\phi_2}{r_{21}^p-1}The Richardson extrapolation is only expected to work well for cases where you have monotonic convergence. For any other convergence condition (see the previous point), your Richardson extrapolated value will likely give you useless results!
Step 5: Calculate the errors
The errors are just the difference in the quantity of interest as we go from one grid level to another, as alluded to above. It can be calculated for the various grid levels as:
- Error from the coarse to medium grid:
\epsilon_{32}=\mathrm{abs}\left(\frac{\phi_2-\phi_3}{\phi_2}\right)- Error from the medium to the fine grid:
\epsilon_{21}=\mathrm{abs}\left(\frac{\phi_1-\phi_2}{\phi_1}\right)Step 6: Calculate the Grid Convergence Index (GCI)
Now we have all the ingredients we need to obtain the grid convergence index. Let's look at the formulas first and then put that into context:
- The grid convergence index for the coarse to medium grid:
GCI_{32}=\frac{1.25\epsilon_{32}}{r_{32}^p-1}- The grid convergence index for the medium to fine grid:
GCI_{21}=\frac{1.25\epsilon_{21}}{r_{21}^p-1}We see that we will end up with two grid convergence index values. These will tell us how much uncertainty is in the mesh as we go from the coarse to medium and medium to the fine grid. If we multiply this value by 100, we get it as a percentage, which is typically how the grid convergence index is reported.
The value of 1.25 is somewhat arbitrary, and if you look into the original paper of Roache, where the grid convergence index was introduced, a value of as high as 3.0 was recommended for parametric studies. This factor is, essentially, a safety factor, and the higher this value is, the larger your grid convergence index, and so we can be more or less conservative with our estimate for the grid convergence index by playing with this parameter. In practice, though, I have found that leaving it to the default of 1.25 works well across a range of applications.
While there are no hard and fast rules about what values are acceptable for the grid convergence index itself, I have found these guidelines to be useful as a starting point:
- Aim for a GCI of about 5%-10% if you are performing parametric studies. Relative errors between simulations will partially cancel, so we don't need a very precise measure of our quantities of interest, especially if we are just interested in getting an idea for the optimal parameter combinations.
- Aim for a GCI of about 1%-5% for detailed studies, i.e. if you want to obtain a precise measure of your quantity of interest.
Step 7: Calculate the asymptotic range
The asymptotic range provides us with an estimate of how much return on investment (in terms of computational cost) we are getting as we are refining the grid. It is calculated as:
AR=r^p\frac{GCI_{21}}{GCI_{32}}If we reach a value of 1 (unity), we have reached the optimum, and refining our grid further will no longer provide us with a more precise measure of our quantity of interest but instead increase our computational cost with no additional gain in precision. A value different from 1 means we may consider changing our grid levels. Say we have a coarse, medium and fine grid with 0.1 million, 0.4 million, and 1.6 million cells, resulting in a value of [katex]AR=0.7[/katex], we may want to increase the number of elements in each grid level.
We may opt to use 0.5 million, 2.0 million, and 8 million instead for an additional grid convergence index calculation, which may then give us [katex]AR=0.996[/katex], indicating that we have reached a fairly low uncertainty in our grid on the finest grid level. We may then look at the grid convergence index for the fine and medium grid (i.e. [katex]GCI_{32}[/katex] and [katex]GCI_{21}[/katex]) and decide which one to take based on the recommendations provide above (i.e. do we want to stay below or above 5%. If both are below 5%, we will take the medium grid to save computational cost).
Step 8: Estimate the optimal number of grid points
And finally, we can also solve the grid convergence index for the refinement ratio, which will allow us to reverse engineer the number of cells we would require, in theory, to obtain a grid convergence index of a specific value. This may be useful if we want to achieve a specific value for the grid convergence index, for example, a value of 1%, to reduce the mesh-induced uncertainties to a minimum, or a value of 10%, to maximise computational efficiency (for parametric studies) while keeping the uncertainty at an acceptable level.
This refinement ratio is calculated as:
r^*=\left(\frac{GCI^*}{GCI_{21}}\right)^\frac{1}{p}Here, [katex]GCI^*[/katex] is the grid convergence index that we want to achieve, which returns the refinement ratio we would need. From the refinement ratio, we can calculate the representative grid spacing, and from that, the required number of points.
Pitfalls: Avoid these common mistakes
The grid convergence index is one of the first things you want to obtain, if you have no other information to go by. But is may not always be the best thing to do; if there are best practices available, and you reasons to trust them, then it is a good idea to follow these best practices, especially if meshing guidelines are included. There is no need to reinvent the wheel.
However, these best practices are not always provided or easy to find, in this case, the grid convergence index is your best protection early on to established results that have an insignificant amount of mesh-induced uncertainty. In the following sections, I want to address common mistakes I see being made over and over again. Try to avoid these as best as you can (though you will not always be able to do so). Exercise your critical thinking and know when and why to distrust your grid convergence index.
Refining your grid not uniformly
This is the single most common mistake, or issue, I see. The grid convergence index was derived for uniform mesh refinement, meaning that we should refine our mesh equally in all direction. This only works for a structured grid, but we can get a fairly close approximation even on unstructured grids.
There are some complications here. If we want to capture the near-wall behaviour with a RANS turbulence model and decide to employ a first cell height that corresponds to a y+ value of 1, then we need to make sure that we will never go above this value in our mesh refinement. Thus, we need to aim for [katex]y^+=1[/katex] on the coarse grid, which will then reduce to [katex]y^+=0.5[/katex] on the medium and [katex]y^+=0.25[/katex] on the fine grid, if we apply strict uniform refinement.
If we started, however, with [katex]y^+=1[/katex] on the fine grid and then applied mesh coarsening to get to the medium and coarse grid, we would get [katex]y^+=2[/katex] on the medium and [katex]y^+=4[/katex] on the coarse grid, respectively. This would result in the boundary layer being incorrectly captured, and quantities such as skin friction or drag coefficients would be less accurately captured.
Furthermore, it is not sufficient to apply mesh refinement systematically in one direction, but instead, it needs to be applied in all direction equally (hence the name uniform mesh refinement). The following figure shows the difference between uniform and non-uniform mesh refinement.

For the uniform mesh refinement case on the left, we see that each surface element has been divided into 4 smaller surface elements. For the non-uniform refinement on the right, we see refinement along the slender edge, but only in one direction.
To exemplify this, take the following mesh refinement study done on a heat exchanger:

We have 6 different grids, and for each grid, some different meshing aspects were varied. This is not necessarily a bad approach; it will reveal how changes in the mesh will affect the solution, which is great. We just can't use this data also to calculate the grid convergence index (which, in fairness, the authors didn't do in this particular study).
A common issue with non-uniform mesh refinement is that you may have oscillatory results for your quantity of interest, and it may either be a converging or diverging behaviour.
Take the following graph, for example:
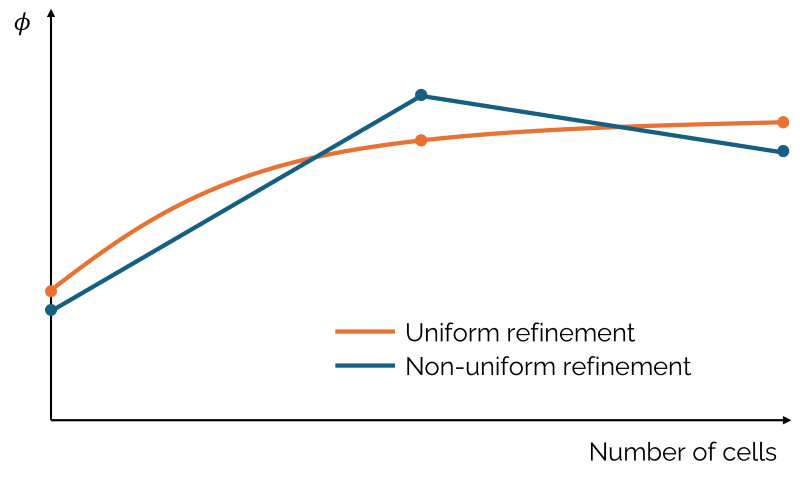
Here, we see that with uniform mesh refinement results in a graph where the quantity of interest reaches an asymptotic limit. For the non-uniform mesh refinement, it is non unusual to see the quantity of interest first increase and then decreasing again (or vice versa). We saw above that this is labelled oscillatory convergence, and this can result in unrealistic grid convergence index values, even if they appear to be low. Check you convergence condition, and always aim for a monotonic convergence condition if you can. This may require meshing again!
Believing the grid convergence index applies equally to structured and unstructured grids
We touched upon this in the previous point, but it is worth reiterating. Since we require uniform refinement, which we can only achieve on structured grids, we technically can't use the grid convergence index for unstructured grids. However, we have gathered a lot of experience in the past decades on the correct usage of the grid convergence index, and we know that it works well for unstructured grids as well, as long as we do not deviate too much from uniform mesh refinement.
Refining your grids too little between coarse, medium, and fine grids
Another common issue is the refinement ratio [katex]r[/katex]. Consider a 1D flow first. If we half the spacing between cells, then, well, we will double the number of cells in our 1D (line) mesh. But in 2D, if we have a quad element and we half the spacing in each direction, then we will generate 4 new quad elements, and in 3D, it gets worse, where one hexahedral element results in 8 new hexahedra being generated. This is shown in the following figure:
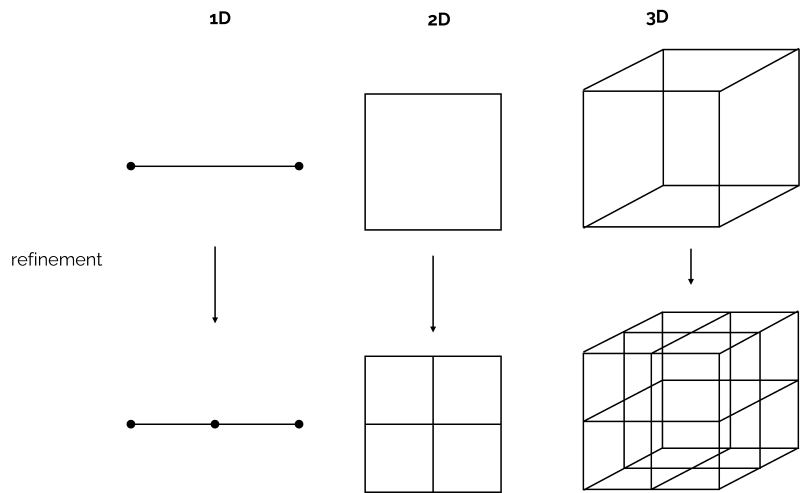
Since we have half the spacing in each direction, the refinement ratio is [katex]r=2[/katex]. Let's think about this for a moment. If our coarse grid contains 1 million cells and we look at a 3D simulation, our medium grid will have 8 million elements, while the fine grid will have 64 million cells. This becomes quickly difficult to handle. Thus, [katex]r=2[/katex] is not realistic in most cases. So we probably want to use a lower value, but how low can we go?
Well, let's consider the extreme case of having 1,000,000 elements on the coarse grid, 1,000,001 elements on the medium grid, and 1,000,002 elements on the fine grid. Technically we fulfil the requirement of having an increase in the number of cells, but our refinement ratio will essentially be [katex]r\approx 1[/katex].
Say this is the mesh around an airfoil, and we are interested in the lift and drag values. How much are these values changing going from 1,000,000 elements to 1,000,001? Probably not by much, and I dare say, not at all! So if the quantities of interest are not changing at all, then the relative difference of the quantities between grid levels will be practically zero.
This is also visualised by the following graph. Here, we have two sets of grids, each set containing three levels of meshes, i.e. the coarse, medium, and fine grid. We see that the first set of grids labelled with [katex]h[/katex] has very similar number of cells, while the second set of grids, labelled with [katex]g[/katex], shows a wider spread between the number of cells going from one grid level to the next.
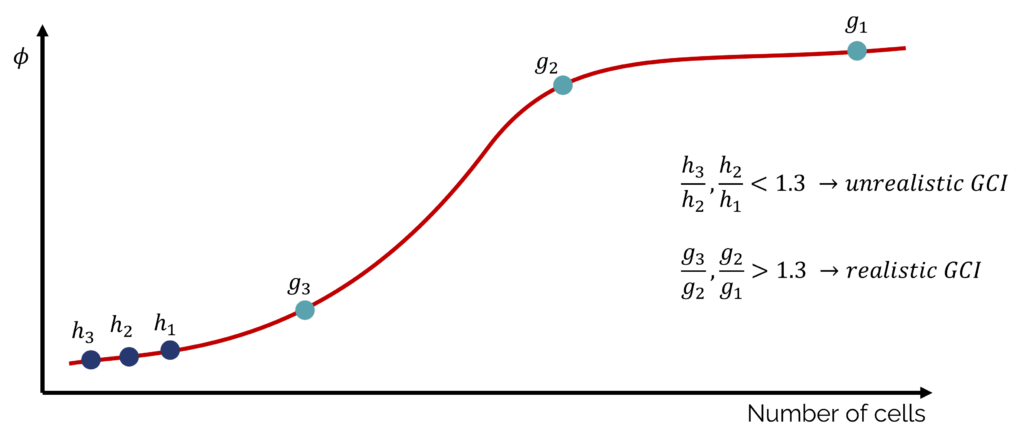
Looking again at the definition of the grid convergence index (here for the medium to fine grid):
GCI_{21}=\frac{1.25\epsilon_{21}}{r_{21}^p-1},we see that the error (relative difference between the quantity of interest between two grid levels, i.e. [katex]\epsilon_{21}[/katex]) will be zero, and thus the grid convergence index will be zero, too (unless we push [katex]r_{21}[/katex] to be close to 1, in which case the denominator will go to zero and our GCI value may be all over the place)! We now falsely believe that we have removed any uncertainty in our grid when, in reality, we have just tricked the equation into giving us a value that we like but that has no significance whatsoever.
To cut things short, Celik et al. suggest that we should aim for [katex]r>1.3[/katex] at a minimum, but the larger we make [katex]r[/katex], the more chance we stand to get a robust and realistic reading on our grid convergence index.
Obviously, you should always check your refinement ratio and ensure that you satisfy at least [katex]r>1.3[/katex]. However, sometimes you may be close to the limit and believe that you are getting a robust grid convergence index calculated. You should also check the calculated order of approximation and check if that is similar to your actual order or approximation. So, if you use a second-order scheme, your calculated order of approximation should ideally be close to that. But if it has a value of, say, 7, you should be alarmed.
Non-uniform refinement + a low refinement ratio will often result in unrealistic orders of convergence being calculated. It is a sign that you should think again about your grid generation strategy if you want to have a realistic reading here. However, there is one more aspect that can also result in an unrealistic reading for the order of approximation (and, by extension, an unrealistic grid convergence index), and this is discussed next.
Using single-point measurements instead of integral quantities
Let's say you want to calculate the grid convergence index for a simple flow through a 2D pipe. Which quantity are you taking as the quantity of interest? Well, your goal of this study is perhaps to test different numerical schemes and how well they can predict the velocity profile, for which we have an analytic solution available, at least for laminar flows. Since you are so focused on the velocity profile, you may then say that the quantity of interest is the max velocity measured at the outlet, which will be located in a single cell.
The grid convergence index may now work as expected, as you have followed all of the steps above to the letter, but the mesh uncertainty that your grid convergence index is calculating is now only applicable to a single point in your mesh. How much value is there in knowing the uncertainty of a single point in your mesh? Well, spoiler alert, not that much!
Sometimes it is better to construct artificial quantities, that you have no interest in, or that do not even make any physical sense. This typically involved integrating a quantity along some boundaries or internal lines/planes to get a single, averaged quantity over an entire mesh region.
In the 2D pipe example, we may want to integrate the velocity over the outlet and use that as our quantity of interest. We now use information on the entire outlet, which is better, but still not perfect. If we opt for the pressure drop along the channel, we exercise the entire mesh, as we need the solution on the inlet, the outlet, and how it develops on the internal mesh to get to that single measurement of the pressure drop.
However, we may also choose to integrate the wall shear stresses on the wall boundaries and use that as a quantity of interest during the grid convergence index calculation. It may not represent anything physical, but it will ensure that they have confidence that the velocity profiles at the wall can be measured accurately.
Coming back to our 2D airfoil example, if we choose to use the lift and drag as our quantity of interest and perform two separate grid convergence index calculations, we may get good values for these quantities, but we have no idea if the wake is resolved well or not. If we are interested in separated flows, it may make more sense to create velocity profiles in the wake and integrate them, then calculate the grid convergence index either for an average of all of them or for each integrated velocity deficit in the wake.
This should bring home the point that the level of uncertainty that you calculate with the grid convergence index is tightly related to the quantity of interest that you are choosing. You have to be aware of how this quantity of interest is calculated so you know which areas of the mesh can be judged based on your grid convergence index. If you don't, you generate a false sense of security by calculating a number behind which you can hide, but it will not help you to address and quantify the real uncertainty that is in your simulation.
Calculating the grid convergence index because you can
As we have seen above, calculating the grid convergence index is really not that difficult. And if our solution is small enough to be easy to mesh, it may be a no-brainer to calculate the grid convergence index. But should you? Let's keep in mind that the grid convergence index is a measure of precision, not accuracy, so even if we have a low grid convergence index, that doesn't mean that we can expect an accurate solution.
Let me ask you this: If you had to make a pick between accuracy and precision, which one would you want to get with a low uncertainty (while the quantity you didn't pick would have a high uncertainty)? I.e., the choices are:
- Low uncertainty in accuracy but high uncertainty in precision
- Low uncertainty in precision but high uncertainty in accuracy
The first choice is the better of the two, why? Well, if we selected the second option, we would get inaccurate results but would be very certain about them, while the first option would give us a high accuracy, but we may not be sure how accurate they are. If we lived in a vacuum, neither choice has a clear advantage over the other, but we do not live in a vacuum, and sometimes we can compare our results against experimental data or high-fidelity numerical simulations.
If I know my results are accurate, but the precision is low, then I can circumvent the issue by looking at experimental data. If I get a close match, then I know my results ought to be good. Since the grid convergence index is only concerned with precision, what value would a grid convergence index study have here?
Well, certainly, it can't hurt to know what the mesh-induced uncertainty is, but let's say you perform your grid dependency study for the lift coefficient and then compare your results against experimental data for lift, drag, and side force coefficients. Now you have some numerical value for the mesh-induced uncertainty for the lift coefficient, but that won't necessarily translate to your drag and side force coefficients. This is a typical mistake I see being made over and over again.
If you have experimental data available, there is no need to bother with a grid convergence index (though you may have a supervisor, a line manager, a reviewer, or a superstitious colleague who religiously believes in the power of the grid convergence index and you have to calculate it for them to not lose trust, credibility, or a job). Instead, you should get a feeling for how many cells you roughly need (i.e. literature review) and then create a similar mesh and compare your results against that set of experimental data.
Tools to calculate the grid convergence index
If you have come to the conclusion that you want to use the grid convergence index from now on in your own simulations, then congratulations to you! It is not difficult to write your own script that implements the equations that we have discussed in this article, but in case you want to use an off-the-shelve solution, let me give you two software solution you can use instead.
pyGCS: A Python-based grid convergence index calculator
If you are familiar with Python and how to install packages with pip, then pyGCS (python grid convergence study, because the name pyGCI was already taken, annoying!) may be the right package for you. I wrote it to automate mainly the reporting of the grid convergence index with all of its parameters. The idea is that you specify all parameters as constructor arguments to a grid convergence index class and then simply tell the class to provide you with the results in the form of a table in either Markdown, LaTeX, or plain text syntax.
To install the package, use pip like so:
pip install pyGCSThen, to work with the code, copy and paste the following code and make changes to the constructor arguments as required:
from pyGCS import GCS
# create a grid convergence study object based on a constant domain volume
gcs = GCS(dimension=2, volume=76, cells=[18000, 8000, 4500], solution=[6.063, 5.972, 5.863])
# output information to Markdown-formated table
gcs.print_table(output_type='markdown', output_path='.')
gcs.print_table(output_type='latex', output_path='.')
gcs.print_table(output_type='word', output_path='.')Here, the volume parameter actually doesn't do anything, so you can set it to 1 if you want and still get the same results. It is required in the calculation, but as long as the domain stays constant in size (which it typically does), it will cancel out in the equations. Then we have two arrays to specify the number of cells and the quantity of interest on each grid level. The order for both arrays has to be the same, i.e. going from the fine to the medium to the coarse grid.
On lines 7-9, we generate the various outputs in either Markdown, LaTeX, or Word format and store them in the current directory. For example, the LaTeX output generated on line 8, after being compiled into a PDF, looks like:

In this particular example, we find that the refinement ratio is above the minimum of 1.3, the asymptotic range value is close to 1.0, and the calculated order of convergence is around 1.53. The numerical scheme used in this example had a nominal order of 2, so some of that was lost, which is typically the case on unstructured grids. The solution on the fine grid had a quantity of interest of 6.063, and the extrapolated value is 6.17, so we aren't too far off, which is also supported by a low GCI value of 2.17% going from the medium to the fine grid.
CFD Toolbox: A chrome extension for the grid convergence index
Ok, that was a bit low-level. The main advantage of pyGCS is that you can produce outputs that are easily integrated into Websites, LaTeX or Word documents. But what if you just want to have a quick way to compute your GCI values and you don't want to write some Python code for it?
Well, let me introduce you to the CFD toolbox, a Swiss army knife of sorts for CFD practitioners. It has all kinds of useful calculators, one of which can be used to compute the grid convergence index. It runs as a Chrome extension and can be added to any chromium-based browser (Chrome, Edge, Brave, etc.)
As you can see from the screenshot on the left, you have similar inputs to make, i.e. the number of cells on each grid, along with the quantity of interest for each grid. You need to specify the dimension of the problem so that the characteristic length-scale can be computed correctly, and that's it.
It reports the same values as the pyGCS tool, and you can specify an optional target grid convergence index that you want to achieve. It will then calculate how many cells you should aim for in your uniform mesh refinement to achieve said grid convergence index.
The output, which is not shown here, will give you the same values as the pyGCS tool shown above.
Summary
Well, there you have it. In this article, we took a deep dive into uncertainties and errors in CFD and concentrated on the grid convergence index as the main tool in our arsenal to manage and quantify uncertainties. Using a serious of 3 grids, and a quantity of interest such as the lift or drag coefficient, we can calculate how much uncertainty we have in the measurement of that quantity on our 3 grids.
Contrary to common belief, the grid convergence index is not a measure to establish accuracy of our simulation, instead, it only specifies how much precision we have in measurements of key quantities of interest in our solution. This means that we may get an accurate result, even if we have a relatively high grid convergence index, but the uncertainty in this measurement is high, i.e. our confidence in the precision is low and thus, even though we may see an accurate result, it may be a fluke. In this case, comparison against experimental data is essential.
While the grid convergence index does not provide us with a measure for how accurate our simulations are (if life was only that easy), it does present one of the best chances we have to gain confidence in our simulations. In some areas, it is an essential piece of evidence to gain trust in your simulations and in the absence of any experimental data or high-fidelity numerical simulation data, it may be our best chance to establish confidence in the results.

Tom-Robin Teschner is a senior lecturer in computational fluid dynamics and course director for the MSc in computational fluid dynamics and the MSc in aerospace computational engineering at Cranfield University.


