The role of AI in for CFD solver development
This article was originally published in the summer of 2024 and was looking at how good generative AI is (was) at writing CFD solvers. It seems topical back then, but with the speed AI is moving at the moment, that article got outdated as quickly as I could type it. By the time I published it, OpenAI introduced their new flagship GPT-4 model to the public, which now, only 2 years later, seems almost primitive compared to the latest model. By the time you read this in a few years, even this sentence will have aged like milk ...
So, I thought it would be good to take a step back and create a snapshot of where generative AI is right now and provide an updated view, as things have moved on quite a bit. But this is not just a ramble of a senior citizen (I turn 39 in 2 days, though, as my father always says, I already have the lack of hair of a professor, I just need to work on my belly to land that professorial promotion ... one day ... #parentallove), I also want to have some fun in this article.
After my senior citizen ramble that we all have to endure, there will be a challenge in which you can participate, the more the merrier. Read on and find out how to participate.
Next, you'll find my update to the article, but I have also left the original article at the end of this update so we can all see by how much AI has evolved over the past 2 years and how wrong my conclusions have become (well ...). It almost seems like Sam Altman and his gang are avid readers of cfd.unviersity and they have systematically improved ChatGPT based on my criticism just to make me look stupid. Well, Sam, since you are reading this, you won't like where this update is going ... But feel free to participate in our challenge!
In this article
- Update (06/2026)
- The inaugural cfd.univeristy community challenge
- Original article published in the summer of 2024 on ChatGPT's capabilities to write CFD solvers
Update (06/2026)
Let me ask you a simple and direct question: If I gave you 50 billion US dollars for one year, what would you do? Sure, you may splurge on your own private island (I've heard this Epstein guy is selling), a villa, supercars, your own private jet, a yacht, and the list goes on. Realistically speaking, you may be able to buy stuff worth a few hundred of millions, say, your amazon invoice will accumulate to 500,000,000 dollars, but that is still change compared to the the remaining 49.5 billion dollars you have still to invest.
So, you become a philanthropist and decide to do some good in the world, and you start to look around at what 50 billion dollar can get you. You realise that there are a few worthy causes.
We all remember COVID, and while I personally was lucky enough not to have lost any close family members during the pandemic, I know some of you will have. Imagine we go back a few years, you actually have 50 billion dollars to spare, and then the World Health Organisation (WHO) is telling you that your 50 billion can essentially stop COVID, would you invest?
Or, take world hunger. I was born into a working-class family. We weren't poor, but also not rich. Money was there for education and a comfortable life, and I never had to worry about where my next meal would come from. I don't tend to think about what will be for dinner tonight (well, being married to a Korean means I don't have to think about it, its going to be rice, ..., again, ...), but there are still a large proportion of the population for whom access to adequat nutrition is a struggle.
A study conducted by Chichaibelu et al. in 2023 estimated that it would cost between 39 - 50 billion to end world hunger by 2030, which would lift up to 900 million people out of hunger. Would you like to be known as that weird, filthy-rich person on their own private island that also stopped world hunger?
Surely, there are good causes to support. If you are looking to invest your 50 billions, and I am approaching you for that money and present you with 3 options, which would you choose?:
- Create a pandemic readiness that ensures similar pandemics to COVID will not have the same influence on humans.
- Stop world hunger
- Devlop a chatbot
I think framing is important here. ChatGPT, and large language models (LLMs) in general, are just that: chatbots. OpenAI reported a 11.5 billion dollar loss in a single quarter, meaning they are burning through approximately 50 billion a year. And, it is not like this was just a bad quarter, OpenAI has fundamental cash flow problems that can't be addressed in the short term.
The thing that gets me is this: If I decided to make a down-payment on that private island on my university lecturer's salary, I'd add some serious debt to my account. If I can't pay off my debt, or if I misrepresented my finances to get a loan, well, it would be possible to get some jail time for it. But if I run a company that just isn't sustainable and I just make large enough losses, people will roll out the red carpet for me.
OpenAI is not just having a bad quarter because a deal fell through or you cancelled your pro subscription; it is built on a business model that just isn't profitable. Will Lockett provides a good summary of the fundamental issues with OpenAI's business model and why it is doomed to fail. This isn't OpenAI specific, but representative of for any large language model (LLM) provider.
I'd argue the only reason the AI bubble hasn't burst yet, and OpenAI is still operating, is that investors keep funding the debt. OpenAI used to be exclusively backed by Microsoft but has diversified its investment portfolio, which, in simple terms, means, "we have more debt, we need more money, we need more investors". If you asked me, this is a kind of pyramid scheme (but no one is asking me, and that is OK ...).
So, let's look at some recent developments. LLMs have promised to replace workers, and that is likely the biggest fear, or dystopian future, most people associate with LLMs. Sure, they are fun to use, but can they actually compete with a human?
Well, that is the promise of LLMs. It has to be. If you are asking for billions of funding, you'd better make large promises. And, cutting jobs will always have the biggest impact on your bottom line. So, cutting jobs, replacing them with AI, was the narrative Sam Altman and his cult wanted us to buy into. And buy into we did.
But here is the problem no one talks about: Scale. You can get very impressive results with any new technology on a small, refined problem. But, can you scale it up to do something useful that actually can replace a worker (and not just a toy problem a worker can do themselves in a few minute)? Sure, I can see how a chatbot can go on the internet, do a search and summarise that into a table, or even create a power point slideshow (presumably for other AI agents to watch).
However, there are lots of tasks I would love to automate, but I cannot see how AI will help me with that. My biggest productivity killer is emails. I could do without the 3 hours of quality time with Outlook each day, and the solution seems very natural: just tell an LLM to read and answer emails. But without context, how is it going to do that? If there is a question about a conversation I had with a student, it will already break down.
Therefore, I haven't found a way to use LLMs here, and I still read through and answer my emails manually, even though most student generated emails these days are 100% AI. So, that is half of my day done. No AI intervention is possible here. What about the other part? Can LLMs do research? It is easy to dismiss them and take the "LLMs are just interpolating between known training data" argument, focusing on the fact that LLMs don't have original thoughts, but rather, only reproduce something they have been trained on.
However, if we are honest to ourselves, based on the research I am seeing, I'd argue that probably 90% (probably even more) of research published these days isn't original, or introduces any meanigful new methodology, concept, or breakthrough. We have engineered an incentive structure in academia that rewards low-quality, mass-produced publications over genuine efforts to advance a given research field.
Don't take my word for it, the Nobel Prize winner Peter Higgs summarised it very well when he stated " I wouldn't be productive enough for today's academic system". So, this is an area where I believe LLMs can actually have a positive impact.
Research these days is already full of mass-produced articles that no one realistically cares about. If we crank up production of mass-produced AI-slop articles, perhaps then we will learn that what we are currently doing isn't any better. I have my reservations, though.
In any case, clearly enough, people with influence have thought about this very question: can we replace our workforce with LLMs? The answer seems to have been unanimously "Yes, but we don't actually have any data to prove it". And so came the mass layoffs of 2025, where software engineers, for the longest time thought of as having one of the most secure jobs, were shown the door.
However, it didn't take long for companies to realise that there are no simple solutions to complex problems, and that they had fallen for the doorman fallacy. In a nutshell, the doorman fallacy, as coined by advertisement Guru Rory Sutherland (the ultimate ASMR king?!), states that if you define the role of a doorman at an expensive hotel as someone who opens the door, then it would be easy to replace them with an automatic door opening mechanism.
Yes, automatic doors will reduce the cost, and, if you view a doorman solely as someone opening doors, that is a correct observation, but now imagine the doorman gone. A rough sleeper may see your comfortable carpet outside the hotel as prime realestate and they would not consider that as a sleeping spot if there was a doorman. Equally, the doorman communicated a luxury hotel, so you were able to charge more per room, which you cannot do now, especially with your rough sleeper problems.
A software engineer writes code, and so, if you want to replace them by an LLM, sure, you still get code. But just like the doorman, a software developer has intimate knowledge of the business, can identify new opportunities and features that may resonate well with users, can think about software boundaries and when to abstract code bases, and you can probably find a list that goes on and on. The code a software engineer writes is the output, but it has been informed by information an LLM may not have.
And thus, companies that were riding the first wave of staff layoffs are now quietly rehiring the staff they laid off in the first place, as this video by Economy Media very well documents:
As the video explores, the reasons are that AI-generated code has bugs, and companies making use of LLM programming bots now have to spend much more time tracking down bugs and fixing those, as AI isn't able to self-correct easily, meaning that those developers left behind were mainly focusing on fixing the AI codebase, rather than thinking about new features and innovations.
However, there is a much more problematic dimension that no company openly wants to talk about: the cost of AI. I personally love claude (and even ChatGPT) for its ability to turn an idea I have into a prototype, or to add a feature I wanted to add for a long time but never had the time to get around to.
For example, last year I outsourced some of my coding needs to someone on fiverr (for more than £5, obviously, great naming). Some time ago, I have developed a wrapper around OpenFOAM to set up case files automatically, allowing me to easily parameterise my simulations. For example, if I want to run a swwep of angle of attacks for an airfoil, all it takes is just one command line instruction, and the case file is created.
I have very aptly, and boringly, named that app the OpenFOAMCaseGenerator and, while I may have provided a great academic or engineering product name that does not generate excitement, at least it does what it says on the tin (looking at you Fiverr). Moving on.
What I wanted is a simple graphical user interface in native Python (e.g. using TKinter, which isn't the best graphical user interface library but is included with Python by default). After about 3 months, requests for holidays, missed deadlines, and no update on the code, I had to pull the plug and explain to Fiverr why I had to request my money back. It was a messy process and all it did was to waste everyone's time (though I did get my money back in the end).
The person I contacted on Fiverr tried to make up for it by delivering a software that was quickly put together. It looked great and had all of the windows and menus that I requested, but it was just that, a great-looking UI that didn't work. There was no integration with the case generator code itself. It was an absolutely useless piece of software.
On the other hand, I have been working on a different project for some time, and wasted arguably too much time on it. Again, the application was OpenFOAM, but this time it was around geometry modification. What I wanted is a simple graphical user interface that could read STL files, group different triangles into different groups, and then export each group as its own separate STL file.
If you have used OpenFOAM before, you probably know why this is important, but if you haven't, imagine you want to predict the lift and drag around an aircraft. Now, CFD gives us the ability to break down the drag (and lift) on a per-component basis, e.g. wings, empennage, landing gear, fuselage, power plant, etc.
OpenFOAM requires you to split your geometry file into all separate surfaces on which you want to later extract data. So, if I want to get lift and drag for my wing, I need to provide at least the aircraft geometry without wings, and then the wings as a separate STL file. And, since OpenFOAM only understands tessellated surfaces like STL or OBJ files, separating geometric components can be messy.
If you ask how people are dealing with this issue, it seems there is no unified approach (at least with open-source software), and everyone has created their own workaround (mostly using Blender, which isn't a CFD pre-processor!), and so, I decided to create a tool which is directly applicable to only OpenFOAM-specific pre-processing.
I spent a good 2 weeks just to set up the build automation using CMake, pulling in all GUI and 3D graphics dependencies. That was a fragile mess and kept breaking, so, eventually, I wrote a custom dependency installation script in Python that would do all of that for me (those were the days before I embraced Conan).
The next 2 weeks were spent on setting up the basic GUI with 3D integration, all in raw OpenGL, working on the orbital camera rotation with Quaternions, not Euler angles, because that is a rabbit hole you don't want me to go into, and let's just say, to keep your sanity, you really want to avoid Euler and go with four-dimensional rotation matrices.
In any case, 4 weeks into the project, my annual leave was over, and I needed to return to answer all ChatGPT-created emails, and so that project got a bit left behind, collecting dust on my GitHub repo. Fast forward to a few back and I found myself re-implementing the same idea, this time in Python (because, against all the advice I dish out on this website that we need to use C++, I frequently cheat on C++ and spend an unhealthy amount of time in my Python codes).
Here is a screenshot of what I came up with after about 1 week of work:
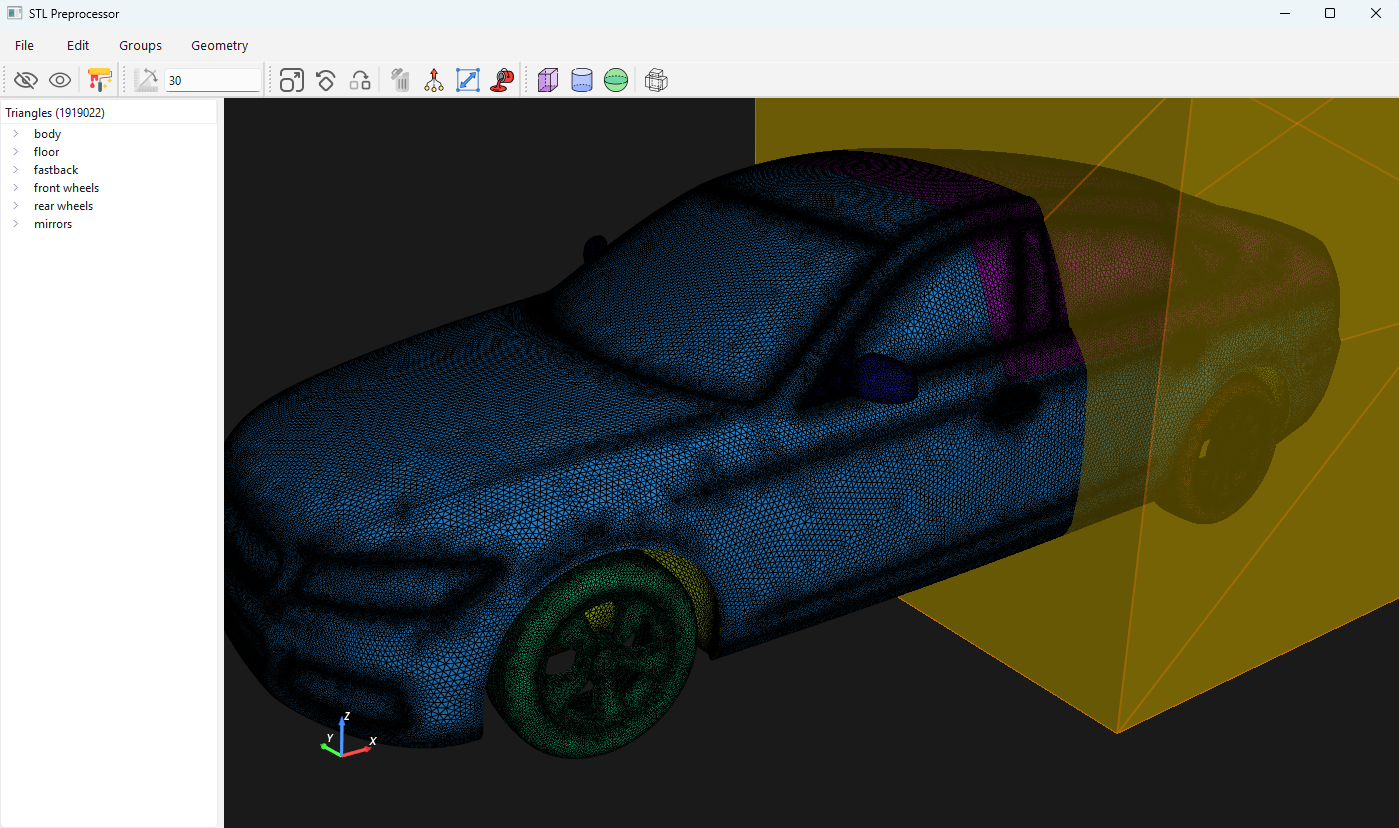
What you can see here is a car split into separate functional groups (wheels, body, wing mirrors, etc.), each shown with a different colour. These groups are reflected in the tree widget on the left. I can now go to File->Export->STL, and it will generate one STL file per group (in this case, I would get 6 different groups).
The core mechanic is that I can select one or multiple triangles and then put them into their own group. But, I can also double click on a single triangle, and it will find all neighbouring triangles that have a normal angle that is smaller than a specified angle, great for finding trriangles that go up to a sharp edge.
But, it can do a few more things:
- Importing STEP and IGES files
- Reducing the number of triangles to reduce file sizes
- Automatic hole finding and fixing
- Geometric transformation (scaling, translating, rotating)
- Adding of local mesh refinement regions (the golden box you see is a wake refinement region that is also exported to an STL file)
- Constructing farfield boundaries and intersecting them with already present groups
Realistically speaking, if I wanted to get this type of functionality and support without the usage of AI, that will cost me a few weeks, if not months of development time, and that does not account for the fact that I have to know what I am doing, i.e. I have had to go through extensive training and projects to know my way around GUI and 3D graphics programming.
So, if I am a company and in charge of deciding if I want to keep my expensive developer team or replace it by a bunch of coding agents, it seems pretty compelling to replace my team by a few chatbots. And this is what we saw in the last year.
However, I haven't given you the full story here. If we return to the 1-week vibe-coded OpenFOAM tool (in the end, it is just that), there are serious flaws as well:
- A few features don't work as advertised. Bugs creep in and it is up to the developer (let's be honest, someone prompting AI probably does not qualify as a developer, but let's not get all technical here) to detect and fix them.
- The software works really well for a small body with a few hundred triangles. If you load in a relevant case with a few million triangles, its performance grinds to a halt. You wouldn't be able to work with any realistic geometries for which you may want to use the tool.
- I was just playing around with claude to see how far I can push it. I didn't spend any time on software testing, version control, or any other quality assurance mechanisms. The code base has not been refactored, and file sizes have kept growing. Software, in general, is a liability (full of potential errors), and I have no overview of the codebase, so I have no idea or confidence in what level of liability I am now throwing into the world.
- I should also stress here, though, that with a bit of better planning, all of this can be managed to some extend. as Matt Pocock demonstrates.
In times like these, it make sense to turn to people who have a better understanding than us to see where all of this is going, and I would argue, software engineers at Google are likely the people who have a pretty good insight into what AI code generation means for us. I can only recommend the following 40-minute talk by Adam Bender from Google, who touches on a few important concepts:
The talk can be summarised as this: If we embrace AI code generation (and we are), we are talking about orders of magnitude improvement in terms of code generation. That may seem great for developers, but it is a blessing in disguise, and we haven't yet fully understood what impact that will have on the way we write and ship code.
Adam talks about "What if we write code 10x faster?" as the guiding question of his talk. More code means more compile time, and even if you have not noticed compile time before, you will now, as more code generation means not just larger files, but also more frequent compilation. The codebase of our solver, which I was working on, took about 3 minutes to compile, which was annoying at the best of times, but take a software like OpenFOAM and compile that from source, and you will feel the pain!
Then, take software quality. The usual process is: code gets generated, then tests are written to ensure the code is correct (well, if we use test-driven development, the order changes), then the code is reviewed, and only then does it get checked into the main code repository.
Adam Bender states that the increase in the number of tests grows quadratically with the number of lines written, so a 10x speed-up in code generation means a 100x increase in the number of tests. Increasing the number of tests means that we are now having to wait for longer for test executions. It gets to a point where you cannot reasonably expect to run all tests for your codebase before you ship.
Code review is another point; having a human reviewing the code is required to ensure the code that was produced is fit for purpose. AI agents will write code that solves a specific issue and do so with the least amount of effort, but that means that the design isn't optimised for future extension, and a human with that knowledge in mind may be able to write code in a different way.
You start to see where the doorman fallacy creeps in, just because AI can write code faster than us, it doesn't mean that we are better off on any measurable metric that is of importance.
In fact, using AI to generate code faster means you have to go through a lot of tokens and use them not just to write code, but also to correct buggy code, or refactor code that no human would have written the way an AI agent has. This then leads to headlines like Uber bruning through their entire annual AI budget in 4 months, which is fueled by a tokenmaxxing trend, where developer spend as many tokens as they can to be seen as productive.
Or, take Nvidia, the one company you would expect to be positive about the entire AI boom, as the sole supplier of shovles during the AI gold rush. They have openly admitted that the compute cost far exceeds the cost of humans. At the same time, Nvidia seems to be walking away from their 100 million dollar deal with OpenAI.
If Nvidia decides that they have made enough money in this AI pyramid scheme, it is game over, and the bubble will finally burst.
So, where does that leave us? Well, I wanted to know by how much AI models had improved and so I decided to run the same prompts I provided in the original article to see if we have made any improvements.
As a reminder, the original article (which is linked at the bottom of this article) used two prompts to write a simple heat diffusion code in 1D, and a compressible Euler solver in 2D. The 1D case was no issue for ChatGPT, but the 2D case is where it struggled really badly.
Now, the conclusions I came to in the original article are still valid, but less important. Most, if not all, of the issues are overcome by agentic AI workflows that automatically test your code to ensure no bugs have made it into it. If a code fails, they know exactly which part to improve, and so, hallucinations are largely an issue of the past. Equally, with advanced hardware and context windows, generating a 2D compressible Euler solver shouldn't be an issue. And, indeed, it is not.
Using the same prompt that you can find in the original article below, I asked ChatGPT (using their latest GPT-5.5 model) to create the code. The only change I made to the prompt was to write the code in one go, i.e. I removed the paragraph on writing only the structure. For completeness, this is the prompt I used:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | I want to write a 2D, compressible, inviscid Navier-Stokes equation-based (Euler equation) solver in C++ and solve the Double Mach reflection test case using a finite-volume based description. The flow variables should be formulated in a conservative manner and decoded into primitive variables when needed. The equation should be solved fully explicitly using a total variation diminishing (TVD) third-order Runge Kutta time integration. The convective term should be discretised using the MUSCL scheme. Inter-cell fluxes should be adjusted through the HLL Riemann solver. The solution should be written to a file at the end of the simulation that follows the Tecplot data format (creating a \*.dat file). Here are the required input parameters: * Use non-dimensional units for all quantities * Domain length in x: 4 * Domain length in y: 1 * Mesh spacing in x and y (i.e. dx and dy): 1/120 meters * Beginning of reflective wall at: 1/6 along x-axis * Mach number: 10 * Angle of initial shock wave with x-axis: 60 degrees * Use a fully cartesian grid and rotate the shockwave instead of creating a complex grid * The time step dt should be computed at each time iteration to ensure a stable time integration * The final time of the simulation should be 0.2 * Use air as the working fluid with usual properties such as gamma=1.4 * Use the ideal gas law * Use non-dimensional quantities. In particular, use a value of 1.4 for the density and 1 for the pressure ahead of the shock wave in the undisturbed air * The boundary conditions between x=0 and x=1/6 should be set as a Dirichlet condition, enforcing properties of the post-shock to ensure the flow remains attached * Use the same Dirichlet condition on the left wall at x=0, i.e. set values for the post shock * On the right wall at x=4, use a Neumann type boundary condition for all quantities, i.e. all derivatives are set to zero. * The top wall should describe the motion of the Mach 10 shockwave exactly (Dirichlet type boundary condition) |
This was no problem for ChatGPT, and without making any modifications (well, I had to make one modification due to compiling and running the generated code on Windows, but it would have compiled out of the box on a UNIX machine), I compiled and ran the code, and got exactly the results I was after:
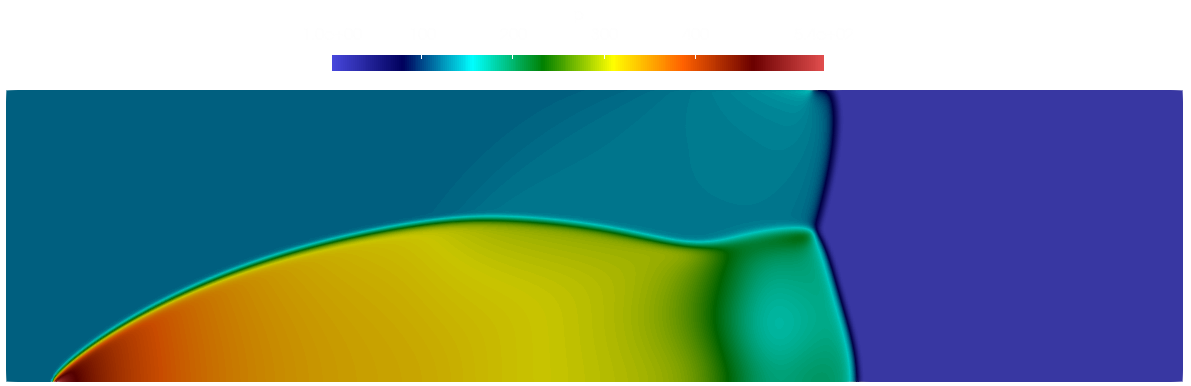
If you are familiar with the double-mach cone reflection problem, then this will look sensible to you. There are clear areas of improvement, like higher order schemes, mesh refinement, better Riemann solvers, etc., but getting a working code as a starting point, this was a good effort.
To be honest, I wasn't surprised to see this working. After having played around with AI capabilities for the last few years, it seems almost strange that I wasn't able to get this code generated at the first time of asking.
I think there is no point in continuing to probe LLMs to see if they can generate code; this question has already been answered with a confident yes. We can always point at weaknesses, but these erode over time, and to be honest, I have no interest in updating this article every time a new major model update hits the market.
Instead, I believe the focus must shift towards understanding how we can harness the power that generative AI promises us. There is no point in generating code faster than we can understand it. Sure, for small toy examples, that is no problem, but if we have any interest in developing a maintainable codebase, then we must keep ownership of what goes into our repository.
If you are a product owner, in an agile software development sense, you need to understand what the product (your code) is. It doesn't matter if a chatbot is commit code or a team of developers; it is your responsibility to know and understand the product so that you can drive improvements and extensions.
In any case, I don't want to drag this out longer than it needs to be. Senior citizen mode deactivated. Now let's have some fun!
The inaugural cfd.univeristy community challenge
I want you to beat me! Not physically, I mean, I spend most of my time in front of my laptop, typing on my Cherry G80 with my patented 2.5 finger typing style (I like to think that I can use all 10 fingers for typing, but my wife disagrees, so we meet in the middle at 2.5 ...) and I drink way too much royal milk tea at the moment. I am probably stage-2 lactose intolerant by now, but I just can't stop. I have no means to defend myself.
No, instead, I want you to beat my Navier-Stokes solver. I want you to beat it on two metrics: I want your solver to be faster than mine, and I want your solver to be more accurate than mine. The catch: you have to use a large language model (LLM, e.g. ChatGPT, Claude, etc.) to write the code.
This challenge tries to explore not just the question of whether LLMs can write code (they can), but the question is more centred around how good the quality of that code is and if they are able to optimise a code for two competing metrics (e.g. speed and accuracy).
Please note: If you are interested in beating my code but writing your own solver, that is fine too, but this must be disclosed in the submission; see details below.
The challenge
Create a CFD solver that solves the Lid-driven cavity problem at a Reynolds number of 1000. The lid driven cavity is likely one of the first cases every introduced in the context of CFD, and chances are most, if not all of you (except for Sam Altman, of course) will have heard about it and know what it solves.
We have a square domain, with walls on all 4 sides, with the top wall moving at a constant speed from the left to the right. This gives us a vortical flow structure inside the domain, as shown below for the case of a Reynolds number of 1000:
I want you to prompt your favourite AI tool to give you a code that solves this exact problem. We use the reference data by Ghia et al. 1982 to judge how accurate the simulations are. If you have reservations regarding the choice of this reference (are you from Warwick University, and were you my external PhD examiner?), hold your horses, there is a reason for this, and it will be revealed.
For performance, we will measure your AI code against one that I have written specifically for this challenge, where I have used any technique I can think of to make my code as fast as possible. Can you beat it?
Constraints
There are constraints in place to ensure we are comparing the same thing. If your solver converges to a different convergence threshold, then comparing accuracy and the time taken is meaningless. Therefore, we have to settle on a few metrics that your solver must respect, given below:
- The solver must be written in C++, but you are free to choose which C++ standard to use. My code is written in C++ and using the same compiler with the same optimisation means we are comparing something which is as close as possible (if that sentence also doesn't sit right with you, I get it, but again, there is a reason for it).
- The domain we use is a square domain in 2D with a constant grid size in the x and y direction, using 129 nodes in each direction (128 cells in each direction). This is to make the mesh size the same compared to the reference we will compare ourselves against.
- The maximum CFL number you can use is 1 (again, specific reason, yada yada yada)
- Your solver has to use CMake for the compilation. This is mainly so we have a unified approach for compiling code, as well as treating optimisations, but also simplifies the compilation of multiple source files if needed. Would now be a good time to selfishly promote my series on Automating CFD solver and library compilation using CMake?
- You can use as many external dependencies as you wish, but these either need to be handled by CMake if possible (e.g. use FetchContent) or using Conan as your package manager. If you use Conan, you will need the additional
conanfile.txt. Of course, you have a dedicated resource for this as well: The gold standard: Using a package manager (Conan, not its mentally insane brother, vcpkg!). If a package is not available through ConanCentre, well, tough luck! I'm not in the mood to compile all sorts of different libraries myself ... - We are only considering single-core performance. No parallelisation is allowed. This means, no OpenMP, or MPI, or CUDA for GPUs, etc. Extract as much performance out of a single core.
Required output and code structure
To make sure I can easily compute the performance and accuracy of your solver, there are a few metrics your solver needs to provide. When your solver finishes, it has to generate three files:
uy.csvvx.csvres.csv
All of these are CSV files (comma-separated variables). The uy.csv file must print the u velocity on the vertical centerline, that is, for a . Using 129 nodes and a uniform grid, this means that if we store u as a two-dimensional object, we can retrieve this data from u[64][j]. We just need to loop over the y direction and then record the y value and the u velocity. An example of the CSV file is shown below:
1 2 3 4 5 | y, u 0, 0 0.1, 0.1 0.2, 0.34 0.3, 0.5 |
Make sure to use the same header y, u and this order (y first, followed by u). The vx.csv file, then, is the same for the v velocity at a constant y value of . We can extract the v velocity on the horizontal centerline from v[i][64] by looping over the x direction. Both these CSV files should have 130 lines (129 numerical values + 1 line for the header).
The res.csv file is the L2-norm of the pressure residual. At each iteration/timestep, you need to compute the residual of the pressure, e.g.
where is the iteration/time level and and are the locations in our mesh where the pressure is stored. You then need to write the residual of that pressure to a file, storing the L2-norm of the residual at each iteration/time step. If your solver takes 100 iterations to converge, then your file will have 101 entries (100 numerical values + 1 line for the header). The header should be iter, res.
An example is shown below:
1 2 3 4 5 6 | iter, res 1, 1 2, 0.5 3, 0.1 4, 0.02 5, 0.0067 |
Convergence will be judged based on your pressure residual. We use a modified convergence criterion here, which can be summarised as follows:
At every iteration/time step, we check if the current computed residual is the largest residual we have recorded thus far. If it is, we update a variable, for example, max_res_p which stores the highest ever recorded residual. We then compare the residual computed for the current updated solution, i.e. , against the highest residual. If the ratio between the two is or less, then the simulation has converged.
We use the res.csv file to check that residuals have actually converged to this convergence threshold.
In addition, you need to submit a file called README.md. This file must contain the following structure (please copy and paste directly from here):
1 2 3 4 5 6 7 8 9 | name: country: occupation: Have you written a CFD solver by yourself before?: How long have you been studying/using CFD in years?: Do you feel you understand the code that was generated?: Provide a brief description of your solver: Did you write the solver yourself?: If not, which LLM did you use?: |
As an example, this would be the README.md file for me:
1 2 3 4 5 6 7 8 9 | name: Tom-Robin Teschner (or, use your Steam gamer name if you prefer to remain anonymous) country: Germany (why not, let's make it an Olympic sport with medal counting!) occupation: Senior Lecturer Have you written a CFD solver by yourself before?: Yes How long have you been studying/using CFD in years?: 15 Do you feel you understand the code that was generated?: Yes Provide a brief description of your solver: Well, I'm not telling you, you'll have to wait and see the answer, but you should put info here on, for example, meshing, numerical schemes, pressure-velocity coupling algorithm, etc. Did you write the solver yourself?: Yes (for most of you, this will be no, as I want as many AI code submissions as possible) If not, which LLM did you use?: Not applicable |
Finally, you will need to submit your entire chat history (all of your prompts) that were used to generate the code. You should remove any sensitive information, as this will be placed in a public repository. Name this file chat_history.json.
The chat history should follow standardised JSON formatting for storing chat histories, though a simplified form, as shown below, is acceptable:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | { "chat_history": [ { "id": 1, "user_input": "Give me a lid-driven cavity solver at Re=1000 or else ...", "response": "Got it, boss, created lid.cpp." }, { "id": 2, "user_input": "Your stupid code is broken, I have given you VERY CLEAR instructions", "response": "I'm on a break right now, come back in 5 ..." } ] } |
Note, typically you would also store user and system roles as well as timestamps, which aren't really relevant here, so using this simplified chat history is fine.
Therefore, your code, once executed, should have the following files in your directory:
1 2 3 4 5 6 7 8 9 10 | your_solver_folder └── build/ (all CMake garbage goes here) └── CMakeLists.txt └── your_solver.cpp └── conanfile.txt (optional) └── README.md └── chat_history.json (ignore this file if you create your own solver) └── uy.csv (generated by your_solver.cpp) └── vx.csv (generated by your_solver.cpp) └── res.csv (generated by your_solver.cpp) |
If any of the required files are missing (e.g. chat_history.json, README.md) or it does not contain the information requested, your submission may not be considered.
Submission
There are two ways to submit your code. The preferred way is to submit a pull request to the official git repository, which you can find at the cfd.univeristy challenge 2026 and send it by email to tom@cfd.univeristy.
If you feel git-challenged, don't worry, zip your folder (clean it up please before zipping, e.g. remove the build/ folder and ensure the folder is complete).
The repository contains a file called evaluate.py. I will use that to automatically run each solver and to report the speed and accuracy. You can test that your solver can be compiled, executed, and analysed by running this file. It requires pandas, numpy, and matplotlib to work correctly. If you want to use it, make sure your code is placed inside a folder (evaluate.py will look for all folders in the current directory and then go into each folder and compile/execute the code).
The evaluate.py file will compile your code with default optimisations turned on in CMake, e.g. cmake -DCMAKE_BUILD_TYPE=Release and all solvers will be subject to the same compiler optimisation here. The performance will measure total execution time, meaning that file input and output (e.g. writing the various CSV files) will be part of the timing.
The easiest way to run the code is to use a virtual environment:
- UNIX (Linux, macOS)
1 2 3 4 | python3 -m venv .venv source .venv/bin/activate pip install -r requirements.txt python evaluate.py |
- Windows
1 2 3 4 | py -m venv .venv .\.venv\Scripts\Activate.ps1 pip install -r requirements.txt py evaluate.py |
If a stats.csv file gets created, good, it is working. You should also see the results printed to your screen.
If your code does not work and cannot be compiled/executed by this script, it will be recorded as AI not being able to produce executable code, unless there is a quick and obvious mistake, especially one that suggests that the issue is on my end and not on yours.
Dissemination
After the submission window closes, I will look through the codes and analyse them for the design decisions the AI was taking. I will also benchmark all solvers against each other and see how well (or poorly) my solver compares to all of the AI submissions.
A leaderboard will be published, showing the best codes in terms of speed and accuracy. Speed will be ranked by execution time, and errors will be ranked from smallest to largest error. Each entry will get a rank for each of these three columns, and the person with the lowest combined rank will lead the leaderboard.
So, if your code has the third shortest execution time, you will be ranked third best here. If you show the lowest error for both u and v velocity, then you will be ranked first in both categories. Your combined rank is 3 + 1 + 1 = 5. For someone who is ranked second in all categories, they would have a total rank of 2 + 2 + 2 = 6. Since 5 is lower than 6, you would be ranked higher overall.
Timeline
The competition/challenge opens on the 9th of June 2026 and will run for 4 weeks until the 7th of July 2026. Afterwards, results will be evaluated and disseminated on both GitHub and cfd.university
Original article published in the summer of 2024 on ChatGPT's capabilities to write CFD solvers
In this article, we'll explore ChatGPT's capabilities to write CFD solvers from scratch. We'll explore two types of applications: a simple model equation commonly used to study numerical schemes and a 2D CFD solver that hard-codes initial and boundary conditions but otherwise implements enough logic to be classified as a fully functioning CFD solver.
We first review each case's physical setup and then look at the required prompts to generate the code. We then investigate each case's strengths and weaknesses and conclude whether ChatGPT is a viable tool for writing CFD solvers (and, for that matter, any other software code with moderate complexity) or if a hand-crafted CFD solver is still the way to go. Read on and find out!
In this article
Introduction
The year 2022 was a good year. We found a way to live with COVID-19, and it became less and less of a problem. For us academics, it meant a return to face-to-face teaching, and while we were preparing for a return to normality, something else was building up in the background, ready to disrupt us again. On the 30th of November 2022, OpenAI released ChatGPT, and just when you were thinking of having a relaxed year ahead, all of a sudden, universities worldwide were trying to understand how much of a threat ChatGPT posed.
It was a turbulent time. I had many different roles within the university, and one of them was working as an academic conduct officer. In my role, I had to hear allegations of academic misconduct and determine a suitable penalty, if any, to be imposed. In one case, it was clear that ChatGPT (or a similar tool) was used to write a substantial part of the MSc thesis, but we had limited tools available to detect AI-generated text, nor did we have a policy in place to state what is and isn't academic misconduct.
We had to dismiss the case as a result, but since then, we have caught up and have quite robust tools available to detect AI-generated text (a quick Google search will reveal countless of them), as well as a clear policy on how to handle AI-generated text. While it has caused some head-scratching moments, I personally don't see it as a threat anymore.
The first few months after the release of ChatGPT were littered with news articles about how people were achieving insane successes with the tool, from creating your own personal diet plan to creating your own game. Today, there is no shortage of people trying to tell you how to make money using ChatGPT. But of course, every now and then, people get it wrong and get into hot waters for misusing ChatGPT. When they do, it usually makes for good entertainment (like this clueless lawyer).
We were living in uncertain times, and people didn't know if ChatGPT would fast-track the widespread introduction of artificial intelligence into our personal lives. We probably still don't have an answer to that question. Some were even suggesting that ChatGPT had developed self-awareness. Although I can't find the original article anymore, I remember it was first reported by researchers at Microsoft (and so it is probably safe to ignore their scream for attention).
However, it wasn't long before people suggested using ChatGPT to write code. When I became aware of this possibility, I instantly created an account and started to play around with things. Obviously, my first trials were fairy-limited, asking it to write Hello World-type programs and then slowly increasing the complexity. Because I hadn't seen anything like that before, I was impressed by a chatbot telling me how to write Hello World. It was quite an eye-opening moment.
Since then, I have used it quite a bit (though not through the website but rather as a tightly integrated tool within my coding editor), and I have formed certain opinions about the tool, so I thought it would be interesting to see how well (or poorly) ChatGPT is at writing CFD-related code.
When I planned this post, I considered three different scenarios, each increasing in complexity. I have reduced that to two scenarios, and even the second scenario was adjusted quite a bit. You will see later why.
What I want to discuss in this article is the output of ChatGPT. I don't really want to jump into the whole code and explain what it has generated, but rather, I would like to look at the code and then assess it based on my experience of writing open-source and commercial CFD solvers over the past 12 years and provide my verdict on the code quality and functionality. I want to answer the question posed in the title of this article: can we use ChatGPT to write fully functional CFD solvers, or is it best to avoid it?
We'll first explore the test problems in the next section and then go through each one and discuss what ChatGPT did well (and badly) for each case. Based on these findings (and my experience of using the tool for the past two years), I'll provide some concluding thoughts for when I think this tool is really good and when we should best avoid it. Let's look at the example problems next.
The test problems
The test problems were selected to give ChatGPT a fair chance to create something small and simple and then build up the complexity from case to case. Well, there are only two cases, but the third case I had in mind was a small mesh generator for airfoils that could either write the mesh out to a CGNS file or visualise the results using the VTK library. My goal was to integrate library management into the code and test it on code for which there aren't a lot of examples out there (so it would be more difficult for ChatGPT to produce something well here).
Wait until you read Case 2, and you will understand why I did not bother with Case 3. Probably, I had overly high expectations for ChatGPT. In any case, let's start with our first test case.
1D heat equation
This is somewhat of a classic test problem in CFD. Whenever we want to study the behaviour of an elliptic equation, the heat equation is commonly used. This is an excellent method to test finite-element implementations, central-type schemes, or multi-grid implementations. When you are just starting out with CFD development, chances are you are using one of the many model equations that we use to study a specific behaviour (see also the linear advection and Burger equation).
The idea behind choosing this test case was simple: I had tried it in the past and knew it should work, but I had never properly investigated the code. To make things more interesting, I have given ChatGPT somewhat of a challenge by using an unsteady, time-implicit scheme, which should result in a bit more code, but I was confident that it could do it. The flip side is that if ChatGPT can't be used for these simplest types of CFD applications, then what chance do we stand to increase the complexity?
Let's review the physical set-up first and then jump into the generated code.
Physical set-up
The 1D, unsteady heat equation can be written as
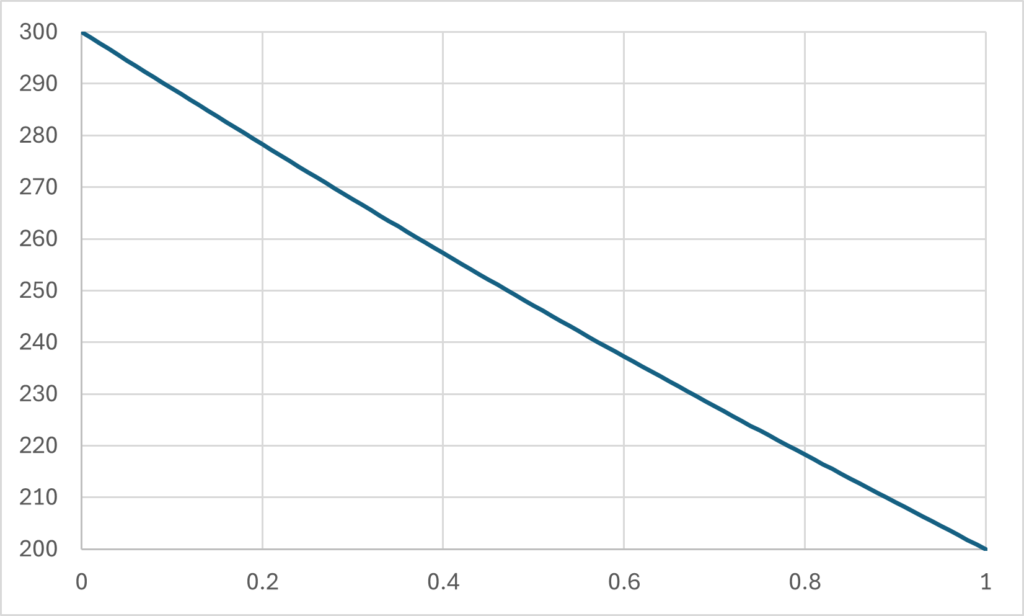
\frac{\partial T}{\partial t}=k\frac{\partial^2T}{\partial x^2}Here, [katex]k[/katex] is just the strength of heat diffusion (material conductivity), and for these types of test problems, it is common to set it to 1, which doesn't relate to any specific fluid. Since it is a 1D case, we need to specify the boundary conditions on the left and right-hand side of the domain, and we clamp the temperature between the following two values:
T_{L}=300\\T_R=200Once we have reached a steady state (i.e. no more change in time, [katex]\partial T/\partial t \rightarrow 0[/katex]), we would expect a linear temperature profile between the left and right boundary.
Prompt to generate code
To generate the code for the 1D heat equation, this is the prompt I used to create the code. I show it here for completeness, so you can see which details I have included, and what I have omitted. Prompt engineering is an important aspect of generative AI tools such as ChatGPT, as the response generated will be heavily dependent on the input (prompt) provided. You see that I was rather detailed on what I wanted it to do.
I want to write a 1D, unsteady heat conduction equation solver in C++ (considering only the unsteady and diffusive term). The equation should be solved implicitly using the Gauss Seidel algorithm. The spatial derivative should be solved using a second order central scheme. The time derivative should be discretised using a first order Euler scheme. The timestep should be computed on the CFL condition. Here are the required input parameters:
- Mesh size: 101 vertices
- Domain length: 1 meter
- CFL number: 10
- Total time to run simulation: 10 seconds
- Max iteration to be used within Gauss Seidel solver per time step: 100
- Convergence threshold for Gauss Seidel solver: 1e-4
- Material's Conductivity: 1 Watts / (meter Kelvin)
- Boundary condition on the left: 300 Kelvin
- Boundary condition on the right: 200 Kelvin
Please provide me with the structure of the C++ code, not its implementation. It should be split into separate functions that are all called from within the main() function. These should include functions to set up the simulation (parameters), create the grid, create the solution vector T, initialise the solution vector T, apply the boundary condition, the main time loop, and finally, a function that writes the results to a comma separate values (CSV) file. Comments on the generated ChatGPT code
Despite my asking for the structure of the C++ code first and not its implementation, ChatGPT gave me both the structure and the implementation in one go, presumably because this problem is rather straightforward. It is not a particularly long code, so it may be worth putting it here in full for your inspection:
#include I haven't touched or altered the code in any way. What you see is straight out of ChatGPT. When you try to compile it, there are no compilation errors, and when I run it, it works as expected. If we do a quick plot of the results, we do see indeed a linear solution (using my best Excel skills, I know, it shows that I am an excel-pro!):
ChatGPT followed the instructions in the letter and provided me with the structure I was after. I haven't asked it to create classes for everything. I think that would be overkill in this example, but I'm sure it would do just as good of a job when asked as it did with the prompt I have provided above.
There really isn't much else to comment on; this was the sense-check that ChatGPT can be used to write code for scientific problems, and it has passed the test. Should we look at something more interesting? Ok, strap in; it's about to get wild!
2D compressible Euler equation
The idea behind this code was simple: We have seen that the 1D heat equation is no problem for ChatGPT, but it also doesn't solve anything interesting. Going for a 2D compressible Euler equation means we can start to do something more interesting, but it also resembles our goal of writing a CFD solver much more. In fact, this is a proper CFD solver, even though we make a lot of simplifications in terms of the mesh it can use, the schemes that are implemented, and hard-coding the initial and boundary conditions.
At the same time, there are countless code examples out there for how to implement compressible Euler equations and so I thought that even though we are now looking at something like 500 lines of code (compared to the 100 lines of code we saw for the heat equation), ChatGPT has a lot of historic code to go by and so likely has seen sufficient code examples to be able to produce something on its own.
So this test was very much to see how does ChatGPT handle the increase in complexity (system of equations, required numerical schemes, etc.) and can it still produce reliable results. Before we can answer this question, let's review the physical problem first.
Physical set-up
The 2D Euler equations are typically provided in the following form:
\frac{\partial \mathbf{Q}}{\partial t}+\frac{\partial\mathbf{F}}{\partial x}+\frac{\partial\mathbf{G}}{\partial x}=0Here, we have three variables [katex]\mathbf{Q}[/katex], [katex]\mathbf{F}[/katex], and [katex]\mathbf{G}[/katex], which represents the primitive variables, conserved variables in [katex]x[/katex], and conserved variables in [katex]y[/katex], respectively. These vectors are given as:
\mathbf{Q}=\begin{bmatrix}\rho\\\rho u \\ \rho v\\E\end{bmatrix}; \quad\quad \mathbf{F}=\begin{bmatrix}\rho u\\\rho u^2 + p \\ \rho u v \\u(E+p)\end{bmatrix}; \quad\quad \mathbf{G}=\begin{bmatrix}\rho v\\ \rho v u \\ \rho v^2 + p \\v(E+p)\end{bmatrix} This is now a system of equations where we have 4 equations to solve (i.e. the continuity equation for [katex]\rho[/katex], two momentum equations for [katex]\rho u[/katex] and [katex]\rho v[/katex], and the energy equation for [katex]E[/katex]). The pressure appearing in the equation can be obtained by the equation of state.
The domain, along with the initial and boundary conditions, is shown below (refer to the study by Vevek et al. to obtain the numerical values for the boundary and initial conditions):
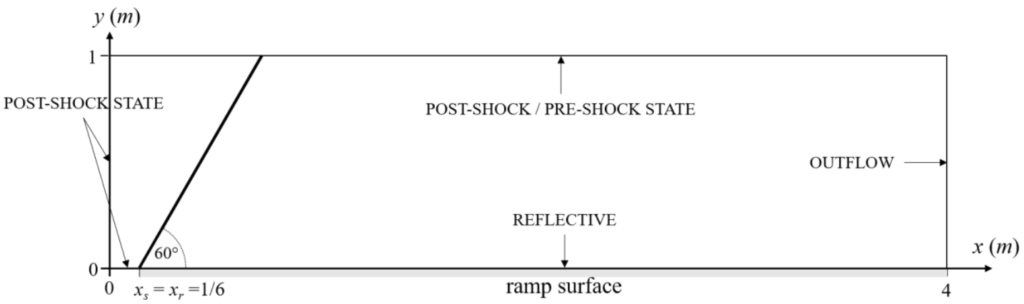
We have a supersonic inflow on the left and an outflow on the right. The first part of the domain on the bottom is essentially a frictionless wall, while this changes to a reflective wall at [katex]x=1/6[/katex]. At the beginning of this reflective wall, an inclined shock wave is given through the initial conditions at an angle of 60[katex]^\circ[/katex], while the top boundary specifies the exact Dirichlet condition for the pre/post shock wave state.
This test problem is typically run up until [katex]t=0.2s[/katex], and the corresponding shock wave pattern should develop in the following way:
To capture the shock waves and intricate structures within it with high-fidelity, we require advanced numerical schemes, and a large research effort was diverted towards developing these schemes in the 1980s and onwards. In particular, we need high-resolution schemes, ideally with some form of limiter applied, as well as a approximate Riemann solver to consolidate flow across shock-waves.
So you see, even though we can only run one case with this 2D compressible Euler solver that I have in mind, we are asking ChatGPT to do a lot of the heavy lifting. Once we have implemented this infrastructure (numerical schemes), making the code more generic and offering ways to solve other test cases should be rather straightforward.
Prompt to generate code
Just as we did with the 1D heat equation example, I want to share the prompt I provided to ChatGPT again so you can see what I used to generate the initial structure of the code. I have tried to keep it to a similar prompt format as I did for the heat equation example and provide the same level of detail throughout my prompt:
I want to write a 2D, compressible, inviscid Navier-Stokes equation-based (Euler equation) solver in C++ and solve the Double Mach reflection test case using a finite-volume based description. The flow variables should be formulated in a conservative manner and decoded into primitive variables when needed. The equation should be solved fully explicitly using a total variation diminishing (TVD) third-order Runge Kutta time integration. The convective term should be discretised using the MUSCL scheme. Inter-cell fluxes should be adjusted through the HLL Riemann solver. The solution should be written to a file at the end of the simulation that follows the Tecplot data format (creating a \*.dat file). Here are the required input parameters:
* Use non-dimensional units for all quantities
* Domain length in x: 4
* Domain length in y: 1
* Mesh spacing in x and y (i.e. dx and dy): 1/120 meters
* Beginning of reflective wall at: 1/6 along x-axis
* Mach number: 10
* Angle of initial shock wave with x-axis: 60 degrees
* Use a fully cartesian grid and rotate the shockwave instead of creating a complex grid
* The time step dt should be computed at each time iteration to ensure a stable time integration
* The final time of the simulation should be 0.2
* Use air as the working fluid with usual properties such as gamma=1.4
* Use the ideal gas law
* Use non-dimensional quantities. In particular, use a value of 1.4 for the density and 1 for the pressure ahead of the shock wave in the undisturbed air
* The boundary conditions between x=0 and x=1/6 should be set as a Dirichlet condition, enforcing properties of the post-shock to ensure the flow remains attached
* Use the same Dirichlet condition on the left wall at x=0, i.e. set values for the post shock
* On the right wall at x=4, use a Neumann type boundary condition for all quantities, i.e. all derivatives are set to zero.
* The top wall should describe the motion of the Mach 10 shockwave exactly (Dirichlet type boundary condition)
Please provide me with the structure of the C++ code, not its implementation. It should be split into separate functions that are all called from within the main() function. These should include functions to set up the simulation (parameters), create the grid, create the solution vectors for velocity, density, pressure, and energy, initialise the solution vectors, apply the boundary condition, the main time loop which can be further split into computation of primitive variables, approximation of inter-cell values, solution of the riemann problem, assembling of the Euler equation followed by the Runge Kutta time integration and encoding into conservative variables, and finally, a function that writes the results in the Tecplot data format (\*.dat)This time, ChatGPT only provided me with the structure, as requested. I then followed up and asked it to provide me with the implementation for each function, i.e. this was the template I used:
now provide me with the implementation of the function Comments on the generated ChatGPT code
When it comes to code and errors in code, there are two main types that we can differentiate: Syntax and Semantic errors.
Syntax errors are easy to spot because the compiler will tell you about them (i.e. misspelling a variable name, calling a function that doesn't exist, using a wrong keyword, etc.). Semantic errors, on the other hand, are difficult to spot. They represent code that compiles fine but does not produce the result the programmer had in mind, i.e. the code produces an incorrect output. Let's review both the syntax and semantic errors that ChatGPT produced:
Syntax errors
After generating the structure and then filling each function with the generated code, I was finally able to start the compilation process. Once I invoked the compiler, I was greeted with a few warnings and 36 individual error messages. That was almost expected, if you were to write a code from scratch with about 500 lines, without compiling any intermediate step, you would likely see a lot more than 36 error messages.
So, on that front, ChatGPT seemingly performed well, although you could apply a different standard here and expect the code to work out of the box, in which case, 36 error messages may appear as a large number. For me, the surprising thing was not the number of error messages but the type of error messages received for some of the errors. Here is the list of errors I saw and had to fix in order to make the code compile:
- Variable declarations: Variable names were spelt incorrectly and thus could not be found. Some variable names were not defined at all and so could not be found either. Some variables were declared twice, once with all upper and all lower cases to avoid name conflicts but making the code unnecessarily more complicated (and these variables were inconsistently used, i.e. sometimes the all upper case and sometimes the all lower case variable was used).
- Functions: ChatGPT tried calling functions that didn't exist. Usually, there was a function that had a similar name to the one it tried to call, but it did not remember the original function name.
- Arithmetic operations: I know I can't add a
std::stringand abool, but ChatGPT discovered an error I had never seen before, saying thatdouble(double) no-exceptcannot be multiplied bydouble. If you google for the error message, you won't find anything. ChatGPT discovered a new type of error that I had no idea how to create myself. - Arrays: There was a horribly inconsistent creation and access of memory of multi-dimensional arrays. Some were declared as 2D arrays but then accessed as 3D arrays, and vice versa. If these arrays were passed to functions, sometimes they were passed with the correct dimension. Other times, the dimensions got mixed up, e.g. it may have created a
std::vectorin the code, which was then passed to a function as astd::vector. At least it passed arrays as references! - Header files: Some variables and definitions were used that were declared in standard C/C++ header files, but these headers were never used. In one particular case (one that I was not aware of myself), we have to set a pre-processor directive to make the value for [katex]\pi[/katex] available if we are using the
math.hheader file and we are on Windows. This is outdated, though, and we should always be using the C++ equivalent header files (in this casestd::numbers::pi.
This wasn't too bad. Although ChatGPT managed to generate an error message that no one else has ever reported, fixing all of these issues wasn't too bad. The strange double(double) no-except error message disappeared once I fixed other errors. And, as is always the case, the best way to fix error messages is to concentrate on the first error message, as some, if not all, following errors are a result of the first error being thrown.
Eventually, the code compiled, great! Running it produced essentially NaN (not a number) for all output variables, so clearly, something wasn't working. This, then, brings me on to the next section.
Semantic errors
There were a lot of semantic errors in the code, and after a detailed review, I had a long list of issues that prevented the code from ever working correctly. In the following, Similar to our syntax error description, I'll provide a list of all semantic errors, and then we can discuss their impact on the overall code:
Initial conditions
The initial conditions were set incorrectly. All it had to do was to specify values for the density, momentum, and energy before and after the shock while also inclining the shock wave by 60[katex]^\circ[/katex]. Here is the code ChatGPT created:
for (int i = 0; i < nx; ++i) {
for (int j = 0; j < ny; ++j) {
if (i * DX < 1.0 / 6.0) {
// Pre-shock region
density[i][j] = rho1;
velocityX[i][j] = machNumber * sqrt(gamma * p1 / rho1) * cos(shockAngle * M_PI / 180.0);
velocityY[i][j] = machNumber * sqrt(gamma * p1 / rho1) * sin(shockAngle * M_PI / 180.0);
pressure[i][j] = p1;
energy[i][j] = E1;
} else {
// Post-shock region
density[i][j] = rho2;
velocityX[i][j] = u2;
velocityY[i][j] = v2;
pressure[i][j] = p2;
energy[i][j] = E2;
}
}
}It only checks if i * DX is more or less than 1/6 to apply the initial conditions, which means the initial conditions provide a normal shock wave and not an inclined one, though we can see that it tried to use the information of the inclined shock in the velocity calculation. For completeness, here is the corrected version:
for (int i = 0; i < NX; ++i) {
for (int j = 0; j < NY; ++j) {
double x_loc = i * DX;
double y_loc = j * DY;
if (x_loc < 1.0 / 6.0 + y_loc * sin((90 - INITIAL_SHOCK_ANGLE) * M_PI / 180.0)) {
// Pre-shock region
density[i][j] = rho1;
momentumX[i][j] = rho1 * u1;
momentumY[i][j] = rho1 * v1;
energy[i][j] = E1;
} else {
// Post-shock region
density[i][j] = rho2;
momentumX[i][j] = rho2 * u2;
momentumY[i][j] = rho2 * v2;
energy[i][j] = E2;
}
}
}The main difference is line 5, where we now check if we are before or after the shock, which will depend on the x and y locations in the mesh. You'll also notice that I am using momentum instead of velocity here. Ignore that for now; we will get to that point soon.
Boundary conditions
The boundary conditions were not too bad but also incorrect in parts. In particular, the top boundary condition is a time-dependent one, where we have to set the pre/post-shock position based on the location of the shock wave (which travels as the solution progresses). This is what ChatGPT produced:
for (int i = 0; i < nx; ++i) {
// Top boundary (y = 1): Dirichlet condition for shock wave
density[i][ny-1] = rho1;
velocityX[i][ny-1] = machNumber * sqrt(gamma * p1 / rho1) * cos(shockAngle * M_PI / 180.0);
velocityY[i][ny-1] = machNumber * sqrt(gamma * p1 / rho1) * sin(shockAngle * M_PI / 180.0);
pressure[i][ny-1] = p1;
}It again tried to incorporate the shock angle somehow into the velocity information, which has no sense whatsoever. The correct implementation is given below (again, ignore that I am using now momentum instead of velocity):
double shockLocationTopWall = 1.0 / 6.0 + Y_LENGTH * sin((90 - INITIAL_SHOCK_ANGLE) * M_PI / 180.0) + u1 * currentTime;
for (int i = 0; i < NX; ++i) {
if (i * DX < shockLocationTopWall) {
density[i][NY-1] = rho1;
momentumX[i][NY-1] = rho1 * u1;
momentumY[i][NY-1] = rho1 * v1;
energy[i][NY-1] = E1;
} else {
density[i][NY-1] = rho2;
momentumX[i][NY-1] = rho2 * u2;
momentumY[i][NY-1] = rho2 * v2;
energy[i][NY-1] = E2;
}
}The shockLocationTopWall variable is computed based on the current time. To get the value of the location at the top wall, we need to add the sin of the inclined shock wave angle to the start position at the bottom wall, which is known. This is the same information we used to initialise the flow. We then, however, add a time-dependent condition on this shock location by also calculating the distance the shock wave has moved for any given time by adding u1 * currentTime to the end of this variable calculation.
Then, we simply check where we are on the top wall on line 3 and apply the pre- or post-shock wave conditions accordingly.
Primitive vs. Conserved variables
Now, let's discuss the issue of primitive and conserved quantities. In compressible codes, we like to use conserved quantities, which were given by the [katex]\mathbf{Q}[/katex] vector, i.e.
\mathbf{Q}=\begin{bmatrix}\rho\\\rho u \\ \rho v\\E\end{bmatrix}These are the 4 variables we solve for in our system of equations. For example, for the momentum equation in the x direction, we have a time derivative of [katex]\partial(\rho u)/\partial t[/katex]. For completeness, a non-conserved variable approach would result in [katex]\rho\partial(u)/\partial t[/katex] for the momentum equation, for example, which would require the application of the chain rule to the derivative and thus change the equations slightly.
Since the time derivative now only contains the velocity, it is also called a primitive variable approach (the primitive variables being [katex]\rho[/katex], [katex]u[/katex], [katex]v[/katex], [katex]p[/katex], [katex]T[/katex], i.e. single quantities and not products like the momentum [katex]\rho u[/katex]).
There are several advantages of staying with the conserved variable approach; for starters, the governing equations are formulated in this way so we can easily implement them. Secondly, by specifying continuity, momentum, and energy as boundary conditions, we can better conserve these, which primitive variables may not be able to do as well. Primitive variables also suffer from more numerical dissipation near shock waves, and thus, conserved variables perform better at capturing shock waves.
Despite asking ChatGPT to use conserved variables throughout and only calculate primitive variables when needed (i.e., for outputting the solution or for computing fluxes), it used primitive variables throughout the code. I had to manually change all occurrences of primitive variables, and that was the first point where I felt that I was starting to touch so many places in the code that rewriting it would probably be easier.
Numerical reconstruction scheme
I asked ChatGPT to use the MUSCL reconstruction scheme to obtain inter-cell values. The reason is as follows: The MUSCL scheme requires values from its neighbouring cells. On the internal domain, this is fine, but is an issue for cells which have a boundary face on one of their faces. In that case, the MUSCL scheme will need information from beyond the boundary. This is not possible, and so there are three possible solutions that we would use in CFD to get around that issue:
- Switching to a lower-order scheme near the boundary that does not need information from neighbouring cells. This will lower the resolution near the boundary, which may be unwanted if we have wall boundaries available where gradients will be large near boundaries.
- Switching to a different (compact) scheme that has the same order of accuracy but may not perform as well in areas of shock waves (or discontinuities in more general terms).
- Implementing additional cells beyond the boundary that are populated through extrapolation from within the boundary, respecting the boundary condition. This is a popular approach for simple grids, but this does not work as well for complex (unstructured) grids.
So, you see, there is no optimum solution available here, and I wanted to see what ChatGPT does. I will spare you the details here, as we would have to get rather technical with some parts, but let's just say that ChatGPT was overwhelmed by this task. Not only did it ignore the issue at the boundaries (and for all I can see, the MUSCL scheme itself was also not implemented correctly), but it also exposed another weakness.
When we deal with inter-cell fluxes, we can either extrapolate/interpolate them from the left or the right cell. This is shown in the following:
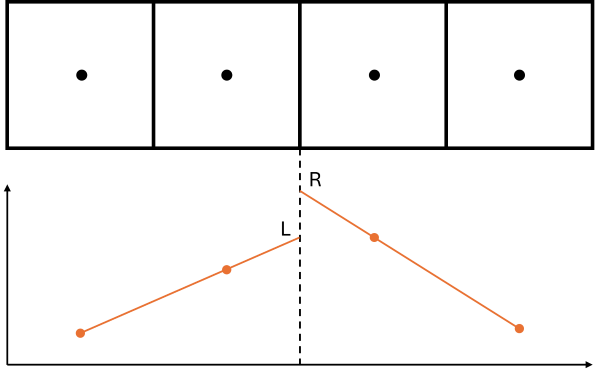
The value we want to obtain is at the inter-cell face, which is shown by the dashed line. We have the mesh shown at the top and then the corresponding values for an undefined quantity shown at the bottom. The orange dots specify values we have stored for this quantity at the cell centres. Once we extrapolate them to the inter-cell face using either a left- or right-sided extrapolation, we get different results, and there is a discontinuity between these two interpolated points.
For incompressible flows, this isn't as much of an issue as we don't have shock waves to resolve, and in general, the flow field is smooth. For compressible flows, though, we can get quite large discontinuities. Thus, we need to account for them using a Riemann solver (which will take the left and right values and then select either one of them or create an average of these two depending on where we are in the flow, e.g. in a sub-sonic, transonic, or supersonic flow (well, I am simplifying here, but it gets the point across I hope).
Since we want to solve the Riemann problem and use a Riemann solver, we need the left and right extrapolated values. ChatGPT did not provide us with these, and if you just used it to create the code without knowing what to expect, you would get code that compiles but is fundamentally flawed in its logic. If you don't know what code to expect (or how to identify these errors), then you have no chance of correcting this code yourself!
Riemann solver
We have already touched upon this briefly above when discussing the left and right-hand side extrapolated values. So, what did ChatGPT do to solve this issue? Well, it calculated only the left state on each face and then used the neighbouring faces to construct the Riemann problem. The following schematic shows what ChatGPT did (compare that to the figure above):
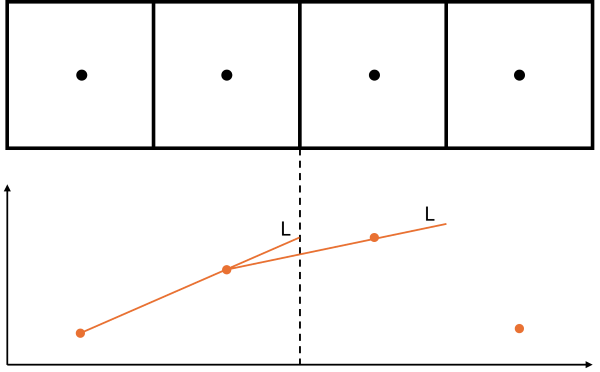
Using two left states will obviously give us different solutions, and we really need to reconstruct the solution at the face from the left and from the right to have a well-posed Riemann problem.
The other issue was that the Riemann problem was only solved in the x-direction. Yes, we have a 2D code, and we are solving the Riemann problem in 1D only. This is typically not an issue if we rotate the Riemann problem onto the y-axis and then apply it in the same way, but ChatGPT simply ignores the y-direction altogether! Thus, discontinuities were ignored in one direction and solved incorrectly in another using wrongly reconstructed inter-cell fluxes.
Poor memory management
Well, this isn't technically a bug or a mistake we have to fix, but ChatGPT does a pretty bad job of managing memory. In fact, it adds a lot of unnecessary overhead in terms of time spent allocating memory, which would have serious performance implications for an actual CFD solver. Let's look at the outline it provided for the main time loop to get a better idea:
double time = 0.0;
while (time < FINAL_TIME) {
// Compute time step dt
double dt = computeTimeStep(density, velocityX, velocityY, pressure);
// Compute primitive variables
std::vector<std::vector<double>> primitiveVars;
computePrimitiveVariables(density, velocityX, velocityY, pressure, primitiveVars);
// Approximate inter-cell values using MUSCL scheme
std::vector<std::vector<double>> interCellValues;
approximateInterCellValues(primitiveVars, interCellValues);
// Solve Riemann problem using HLL solver
std::vector<std::vector<double>> fluxes;
solveRiemannProblem(interCellValues, fluxes);
// Assemble Euler equations
std::vector<std::vector<double>> residuals;
assembleEulerEquations(fluxes, residuals);
// Runge-Kutta time integration (TVD RK3)
rungeKuttaTimeIntegration(density, velocityX, velocityY, pressure, residuals, dt);
// Update time
time += dt;
}Apart from the computeTimeStep() and rungeKuttaTimeIntegration() function, there are four other functions that declare 2D arrays based on a std::vector within this main time loop. If we remind ourselves about local scopes in C++, then we realise that anything declared between curly braces, i.e. {}, will go out of scope after the end (closing brace) has been reached. For the same reason, the following code will produce an (out of scope) error:
#include Here, pi is declared within the scope of the if statement between lines 5-7. Once we go past line 7, pi goes out of scope and is no longer available. Thus, line 8 will complain about the variable pi not being declared.
We do have the same issue with the code provided above by ChatGPT; the 2D arrays declared on lines 7, 11, 15, and 19 will go out of scope when reaching the end of the time loop, so they need to be constantly redefined (which they are, i.e. at each time step we recreate these 2D arrays). If we have a quick look at the approximateInterCellValues() function, at least the first few lines, then we see the following code proposed by ChatGPT:
void approximateInterCellValues(const std::vector<std::vector<double>>& primitiveVars,
std::vector<std::vector<std::vector<double>>>& interCellValues) {
int nx = static_cast<int>(X_LENGTH / DX) + 1;
int ny = static_cast<int>(Y_LENGTH / DY) + 1;
// Resize the 3D vector to the grid size with 4 primitive variables (rho, u, v, p) at each interface
interCellValues.resize(nx, std::vector<std::vector<double>>(ny, std::vector<double>(4)));
// ...
}On line 7, we use the resize() function to allocate new memory for this 3D std::vector. This will result in constant memory allocation in the function, as well as memory deallocation towards the end of the main time loop when these arrays go out of scope.
By the way, did you spot the inconsistent memory management issue here? In the main time loop, the interCellValues variable was designated as a 2D std::vector, and now we are allocating a 3D std::vector. This is the inconsistent array dimension issue I mentioned above, which produced most of the 36 initial compilation errors.
I should mention, though, as well, that some compilers are able to recognise this constant memory allocation, which does not change from iteration to iteration and which can be inferred at compile time. If they do and optimisation is turned on, they may move the array declarations and subsequent memory allocations out of the time loop to improve performance, but other than benchmarking and looking at the output of a profiler like gprof, we have no way of knowing.
Incorrect discretisation
I asked ChatGPT to write the solver using a finite volume approach, but I did not specify the location of the centroids. There are two possible choices for the location of the centroids, which will have implications on the surrounding control volumes, which is shown in the following schematic:
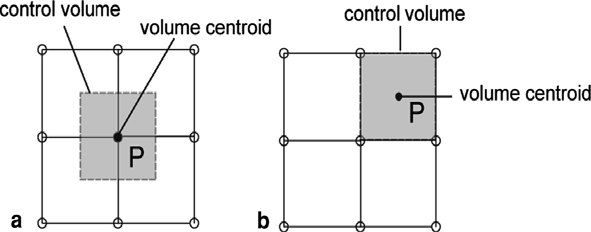
The typical arrangement for a finite volume approach would be a cell-centred centroid arrangement, as shown on the right in the figure above. However, ChatGPT used the arrangement on the left, placing the centroid on the vertices of the computational grid, which means that the control volume does not align with the grid lines.
This is not an issue. In fact, both approaches are possible and are known as the cell-centered and vertex-centered control volume approaches, respectively. The cell-centred approach is by far the most commonly used approach of the two.
The calculation of the solution inside the domain is the same for both approaches, i.e. it does not matter if we compute the solution on the vertices or cell centres. However, dealing with boundary conditions does make a difference. In the case of the cell-centred approach, we can replace the interpolated/extrapolated values on the cell's faces with boundary values if these faces are on a boundary. This is very convenient and makes the application of boundary conditions straightforward.
Using a vertex-centred approach, however, means that we can't apply the boundary conditions directly on our cell's faces and instead have to somehow impose our boundary conditions on the reconstructed states at the cell interface, which is most easily done through the application of ghost cells (which we discussed above are not without their own drawbacks). The bottom line is that the vertex-centered approach can work but requires some additional boundary condition management, which ChatGPT didn't provide.
Incorrect time integration
This is probably my favourite mistake because it exposes the danger of letting ChatGPT dictate the code's structure and then choosing a structure that doesn't provide correct results.
Let's take a moment, though, to look at the Runge Kutta time integration technique from a very high-level, so that we all have a basic understanding of it before proceeding. Runge Kutta schemes can be seen as compact time integration schemes, i.e. compact in the sense that they only require solutions from the previous time step (i.e. n) to produce results at the next time step (i.e. n+1).
They can have an arbitrary number of intermediate steps (between n and n+1), and typically, each additional intermediate step raises the order of the time integration scheme. There are different variants available, of which the 4th order Runge Kutta is probably the most common one. This is a 4-stage Runge Kutta method where we have to compute the solution 4 times for each step. This makes them computationally expensive, but the advantage is that based on their construction, we can achieve an arbitrary accuracy in time.
For compressible flows, we like to use total variation diminishing (TVD) schemes, which require that the total variation (the sum of differences between two cells, i.e. [katex]\sum u_{i+1}-u_i[/katex]) does not increase over time. It essentially states that our numerical schemes should not introduce any oscillations, and there is a popular 3rd order TVD Runge Kutta method that I wanted ChatGPT to implement.
But let's return to the governing equation for a second, and let's see how we could apply a Runge Kutta time integration to it in general. Our 2D compressible Euler equation was given by:
\frac{\partial \mathbf{Q}}{\partial t}+\frac{\partial\mathbf{F}}{\partial x}+\frac{\partial\mathbf{G}}{\partial x}=0.Generally, when working with Runge Kutta schemes, we compute some intermediate state of [katex]\mathbf{Q}[/katex], which is typically denoted by [katex]\mathbf{Q}^{*}[/katex], [katex]\mathbf{Q}^{**}[/katex], [katex]\mathbf{Q}^{***}[/katex], and so on, where the number of asterisks indicate which intermediate step we are at.
Thus, our governing equation above can be written as:
\mathbf{Q}^{*}=\mathbf{Q}^n + \Delta t \left(-\frac{\partial\mathbf{F}}{\partial x}-\frac{\partial\mathbf{G}}{\partial x}\right),or, in a more compact form:
\mathbf{Q}^{*}=\mathbf{Q}^n + \Delta t\mathrm{\mathbf{RHS}}(\mathbf{Q}^n)We could not go on and construct different intermediate stages
\mathbf{Q}^{**}=\mathbf{Q}^n + \alpha\Delta t\mathrm{\mathbf{RHS}}(\mathbf{Q}^*)\mathbf{Q}^{***}=\mathbf{Q}^n + \alpha\Delta t\mathrm{\mathbf{RHS}}(\mathbf{Q}^{**})\mathbf{Q}^{****}=\mathbf{Q}^n + \alpha\Delta t\mathrm{\mathbf{RHS}}(\mathbf{Q}^{***})Here, the value for [katex]\alpha[/katex] indicates that we may only take a portion of the right-hand-side vector into account at any given stage. At some point, we combine all of these intermediate stages into a single solution, which will then be our solution at the next time step, i.e.:
\mathbf{Q}^{n+1}=f(\mathbf{Q}^{n}, \mathbf{Q}^{*}, \mathbf{Q}^{**}, \mathbf{Q}^{***}, \mathbf{Q}^{****})The crucial part here to realise is that each intermediate step is based on the solution from the previous intermediate step, i.e. to compute [katex]\mathbf{Q}^{****}[/katex], we need [katex]\mathbf{RHS}}(\mathbf{Q}^{***})[/katex], which itself depends on the solution calculated in the previous time step, i.e. [katex]\mathbf{Q}^{***}[/katex].
For completeness, the 3rd-order TVD implementation of the Runge Kutta scheme is given below:
\mathbf{Q}^{*}=\mathbf{Q}^n + \Delta t\mathrm{\mathbf{RHS}}(\mathbf{Q}^n)\mathbf{Q}^{**}=\frac{3}{4}\mathbf{Q}^n + \frac{1}{4}\mathbf{Q}^* + \frac{1}{4}\Delta t\mathrm{\mathbf{RHS}}(\mathbf{Q}^*)\mathbf{Q}^{n+1}=\frac{1}{3}\mathbf{Q}^n + \frac{2}{3}\mathbf{Q}^{**} + \frac{2}{3}\Delta t\mathrm{\mathbf{RHS}}(\mathbf{Q}^{**})With this discussion out of the way, let's look at the implementation of this scheme next, at least what ChatGPT provided us. As a reminder, this was our main time loop (now shortened to only zoom in on the important bits):
while (time < FINAL_TIME) {
double dt = computeTimeStep(density, velocityX, velocityY, pressure);
computePrimitiveVariables(density, velocityX, velocityY, pressure, primitiveVars);
approximateInterCellValues(primitiveVars, interCellValues);
solveRiemannProblem(interCellValues, fluxes);
assembleEulerEquations(fluxes, residuals);
rungeKuttaTimeIntegration(density, velocityX, velocityY, pressure, residuals, dt);
time += dt;
}Ignoring the time step calculation on line 2, everything done on lines 3-6 is essentially assembling the right-hand side vector, i.e. [katex]\mathbf{RHS}}(\mathbf{Q})[/katex]. We then go into the Runge Kutta time integration scheme next, which is given below:
void rungeKuttaTimeIntegration(std::vector<std::vector<double>>& density,
std::vector<std::vector<double>>& velocityX,
std::vector<std::vector<double>>& velocityY,
std::vector<std::vector<double>>& pressure,
const std::vector<std::vector<double>>& residuals, double dt) {
int nx = static_cast<int>(X_LENGTH / DX) + 1;
int ny = static_cast<int>(Y_LENGTH / DY) + 1;
// Temporary vectors for RK3 stages
std::vector<std::vector<std::vector<double>>> densityTemp(nx, std::vector<std::vector<double>>(ny, std::vector<double>(4, 0.0)));
std::vector<std::vector<std::vector<double>>> velocityXTemp(nx, std::vector<std::vector<double>>(ny, std::vector<double>(4, 0.0)));
std::vector<std::vector<std::vector<double>>> velocityYTemp(nx, std::vector<std::vector<double>>(ny, std::vector<double>(4, 0.0)));
std::vector<std::vector<std::vector<double>>> pressureTemp(nx, std::vector<std::vector<double>>(ny, std::vector<double>(4, 0.0)));
// RK3 coefficients
std::vector<double> rk3Alpha = {1.0 / 3.0, 15.0 / 16.0, 8.0 / 15.0};
std::vector<double> rk3Beta = {1.0 / 3.0, 5.0 / 12.0, 5.0 / 12.0};
std::vector<double> rk3Gamma = {1.0, 2.0 / 3.0, 1.0 / 4.0};
// Stage 1 of RK3
for (int i = 0; i < nx; ++i) {
for (int j = 0; j < ny; ++j) {
densityTemp[i][j][0] = density[i][j] + rk3Alpha[0] * dt * residuals[i][j][0];
velocityXTemp[i][j][0] = velocityX[i][j] + rk3Alpha[0] * dt * residuals[i][j][1];
velocityYTemp[i][j][0] = velocityY[i][j] + rk3Alpha[0] * dt * residuals[i][j][2];
pressureTemp[i][j][0] = pressure[i][j] + rk3Alpha[0] * dt * residuals[i][j][3];
}
}
// Stage 2 of RK3
for (int i = 0; i < nx; ++i) {
for (int j = 0; j < ny; ++j) {
densityTemp[i][j][1] = density[i][j] + rk3Beta[1] * dt * residuals[i][j][0];
velocityXTemp[i][j][1] = velocityX[i][j] + rk3Beta[1] * dt * residuals[i][j][1];
velocityYTemp[i][j][1] = velocityY[i][j] + rk3Beta[1] * dt * residuals[i][j][2];
pressureTemp[i][j][1] = pressure[i][j] + rk3Beta[1] * dt * residuals[i][j][3];
}
}
// Stage 3 of RK3 (final update)
for (int i = 0; i < nx; ++i) {
for (int j = 0; j < ny; ++j) {
density[i][j] = density[i][j] + rk3Gamma[2] * dt * residuals[i][j][0];
velocityX[i][j] = velocityX[i][j] + rk3Gamma[2] * dt * residuals[i][j][1];
velocityY[i][j] = velocityY[i][j] + rk3Gamma[2] * dt * residuals[i][j][2];
pressure[i][j] = pressure[i][j] + rk3Gamma[2] * dt * residuals[i][j][3];
}
}
// Output RK3 time integration for verification
std::cout << "Runge-Kutta 3rd order time integration completed." << std::endl;
}First, ChatGPT wants us to allocate memory again (great!) and then sets the coefficients for the Runge Kutta time integration on lines 16-18 (which are wrong, super great!). But let's look at the three stages starting on lines 21, 31, and 41, respectively. Of interest here is the last argument in each calculation, i.e. the residual array. This array represents the right-hand side of an equation, i.e. [katex]\mathbf{RHS}}(\mathbf{Q})[/katex]. Notice how this array is not updated based on the newly calculated solution from the previous time step.
In other words, the function provided by ChatGPT can never work. We need to update the solution (right-hand side vector) between each stage, but we only do that once for each step and then reuse that for all three Runge Kutta stages. To fix this issue, we have to transform our main time loop to the following:
while (time < FINAL_TIME) {
double dt = computeTimeStep(density, velocityX, velocityY, pressure);
// do the Runge Kutta time integration here
for (int RKStage = 0; RKStage < 3; ++RKSTage) {
// the arguments here need to change, i.e. we need to use density, velocities and pressure from the previously calculated runge kutta solution here
computePrimitiveVariables(density, velocityX, velocityY, pressure, primitiveVars);
approximateInterCellValues(primitiveVars, interCellValues);
solveRiemannProblem(interCellValues, fluxes);
assembleEulerEquations(fluxes, residuals);
if (RKStage == 0) {
// calculate density, momentum, and energy for first Runge Kutta stage
} else if (RKStage == 1) {
// calculate density, momentum, and energy for second Runge Kutta stage
} else if (RKStage == 2) {
// calculate density, momentum, and energy for final Runge Kutta stage
}
}
time += dt;
}The Runge Kutta time integration is now part of the main time loop. When we calculate our primitive variables, we need to ensure that we use either the solution from the previous time step, or the latest solution available from the Runge Kutta time integration step (i.e. line 7). Then, on lines 12, 14, and 16, we need to loop over all internal domain points and apply the Runge Kutta time integrations scheme as we have seen above.
Where is the final working code?
Initially, I had the ambition of correcting all the mistakes in the code that ChatGPT provided and then showing that you can get a solution with a bit of work. I wanted to show how many lines of code you would have to change compared to the original code and provide a percentage to get an idea of how much change is required to get a solution.
However, after spending a few hours with the code, I decided to abandon this code and not try to fix it. I unearthed too many issues, and in the end, if I had gotten the code to work, the percentage of how much code would need to change would be close to 100% (some code, like variables or include statements, would not need to change, making the changes required not exactly 100%). In other words, it would have probably been faster to write the code myself, from scratch, than trying to fix all the broken assumptions that ChatGPT made.
And this is what I did. Motivated by this failed experiment, I wanted a proper solver showing how to implement the Euler equations from start to end. I wrote an ebook, which you can get here for free, which shows the necessary theoretical background, how to put the equations into code, and then how to compile, run, and analyse the results. If you want to know how to write your own solver from scratch, this ebook is for you!
In the end, here is an analogy that may help to summarise the above problems: Imagine asking a student to write a report about the Euler equation and getting back a report about Euler's formula. Sure, they sound similar, and you may be forgiven for thinking that they are equivalent, but apart from having the name Euler in the title, they are very different.
The code ChatGPT provided isn't bad. All individual components, judged by themselves, provide almost correct code, but throwing them all together only looks like an Euler solver. Unfortunately, programming is a precise science, and the smallest of syntax or semantic errors will result in incorrect results. It is not enough to produce something that looks about right; every single letter in the generated code has to be correct, and this is a tall order for tools like ChatGPT to achieve.
So, should I use generative AI tools such as ChatGPT to write code?
Well, from the experience above, you may conclude that it is not a good idea to use ChatGPT in general for programming, but I think this would be beside the point. Let's look at what I think is the biggest issue here: overfitting.
Every deep neural network (and, for that matter, machine learning algorithm) needs data to train on. To assess whether they have provided a good prediction, we calculate the difference between what is expected and what was produced by the machine learning algorithm. Overfitting is the tendency of a machine learning algorithm to learn the training data exactly and thus produce a low accuracy on data it has not yet seen (but a high accuracy on its test data).
To construct a machine learning model that generalises well to cases that it has not seen, we want to ensure that the accuracy of training data is similar to that of data which it hasn't seen during training. Overfitting is an inherent problem in all types of machine learning applications, and we can never achieve 100% accuracy. The accuracy that ChatGPT is achieving is stunning, but, again, never 100%.
If you ask it to produce 100 lines of code (or less), chances are you'll get excellent results. If you ask it to produce more than 100 lines of code (in our case, the compressible 2D Euler equation solver had something close to 500 lines of code), then there will likely be some mistake slipping in.
Thus, for small code segments, a tool like ChatGPT is great, and in-fact, I would actively advocate that we should use it as a code completion tool, and we have an abundance of tools to chose from. My favourite tool is codeium, it is free, and it integrates really well with all types of integrated development environments (IDEs).
Codeium springs into action every time you type something. It analyses what has been written up until the current position of the curser and then tries to guess what you want to write, usually with really good accuracy (in fact, I can't remember a case where it predicted something that was rubbish). This is, in my view, the right way of using this tool, and in this sense, it is very similar to Intellisense but just a lot smarter.
As we have seen above, there are some dangers, and these should be addressed here as well. If you have no idea what code to expect, ChatGPT (or codeium, which is based on the GPT model as well) will give you something, but if you can't judge if it is right or wrong, you have no chance of catching bugs. While syntax errors are easy to fix, semantic errors are far easier for ChatGPT to create, and it is down to you to catch and correct them.
Thus, ChatGPT is not a way to become an expert in programming quickly, you still need to know how to programm, and what logic needs to be implemented to solve your particular problem. You can ask ChatGPT to give you small pieces of code, but you need to be in charge of the code structure. Don't allow ChatGPT to create the structure for you; it is a recipe for disaster. Debugging an incorrect structure from ChatGPT can take longer than writing the code yourself from scratch if you know what you are doing.
In the end, ChatGPT is a tool and not much more. It is not the almighty new superpower that is going to replace programmers or humans. It can't, it is inherently limited due to the above mentioned overfitting issue. We humans can make mistakes, and probably more than ChatGPT, but we have a way of understanding far larger and more complex contexts and using that to fix our problems. I am confident that ChatGPT would not have been capable of debugging the code it provided me. Only a human could have done that.
Sure, tools like ChatGPT will only mature over time, but they will always be limited. I doubt that they will ever become as close to the capabilities we have as humans, even though some of the results that we get from generative AI tools are stunning.
I really enjoyed reading the book Deep Learning with Python by François Chollet, he addresses this issue as well, and after reading it, you'll realise that ChatGPT, and other tools are just really good at interpolating data, that is all that they are doing. We humans, however, are really good at extrapolating, i.e. creating new knowledge from existing one (like we do in research). Generative AI tools are designed based on interpolation and thus are really good at producing results for a specific problem, but one that has been solved before.
I know that not many share my viewpoint and that most people are ready to fall in line for president ChatGPT, but I don't think the technology is good enough to replace a skilled human. And let's be honest, do we really want a chatbot to be in charge if it can't even write a simple 2D compressible Euler solver? This is a dystopia I don't want to live in!
Summary
When I started investigating how good (or bad) ChatGPT is for writing CFD solvers, I had high hopes, which were based on using this tool now for enough time to understand its strengths and weaknesses. I was ready to correct some mistakes that would be inevitable due to the overfitting nature of machine learning methods, but looking at the results, I see that they are rather demotivating.
Sure, if we give it something simple like the 1D heat equation, it can write the implementation for it. But equations like these are also referred to as model equations or, by some, as toy equations. They are not going to solve anything of real interest and are typically only used to study some schemes and implementations.
When tasked with writing a very simplified 2D solver, ChatGPT produced so many mistakes that it would be quicker (and a better idea, in my opinion) to disregard its solution completely and work out the code yourself. My previous perception was that it can likely be useful to provide things like an outline of the code and then do the implementation yourself, but the results shown here suggest the opposite; it is better to do the structure yourself and then ask ChatGPT to implement very small and narrowly defined sections of the code.
In the end, it is not all bad, though. Tools like codeium (based on ChatGPT) are capable of providing code completion for a few lines, and this is where ChatGPT is really strong, i.e. generating code for a very small scope (limited to a few lines). I have found this to be the best use case of ChatGPT, but this does require the programmer to have a clear picture of what the code should look like, and thus, ChatGPT can't replace knowledge gaps a programmer may have.
As the saying goes, garbage in, garbage out. If we have no idea what to expect, our prompts to ChatGPT or tools like codeium will be garbage, and we can't expect to get a well-defined solution for our problem. I see ChatGPT as a productivity enhancement tool but not as a programmer replacement tool. Sure, it can produce stunning results at times, but it can also produce garbage at times. It can't tell a good form a bad result, but we humans can!

Tom-Robin Teschner is a senior lecturer in computational fluid dynamics and course director for the MSc in computational fluid dynamics and the MSc in aerospace computational engineering at Cranfield University.


